 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating BERT Inference for Sequence Labeling via Early-Exit
Paper and Code
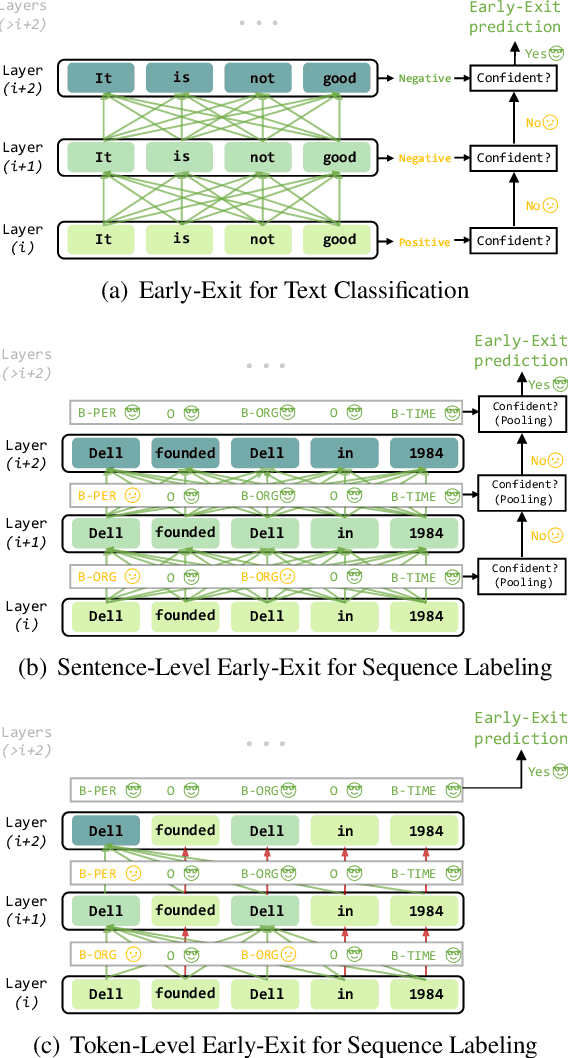
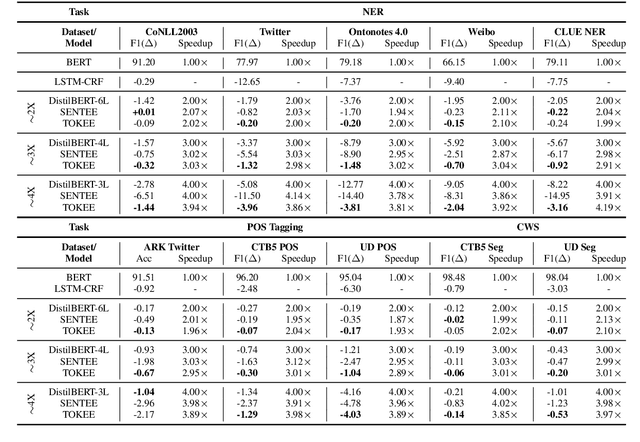
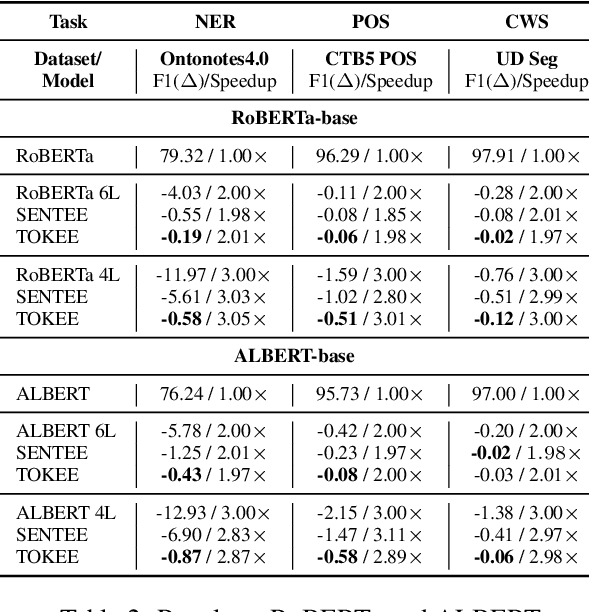
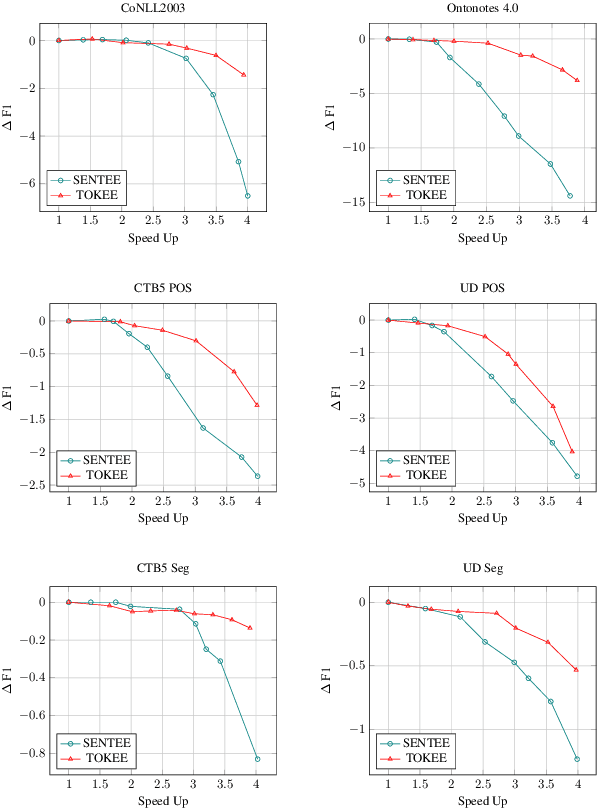
Both performance and efficiency are crucial factors for sequence labeling tasks in many real-world scenarios. Although the pre-trained models (PTMs) have significantly improved the performance of various sequence labeling tasks, their computational cost is expensive. To alleviate this problem, we extend the recent successful early-exit mechanism to accelerate the inference of PTMs for sequence labeling tasks. However, existing early-exit mechanisms are specifically designed for sequence-level tasks, rather than sequence labeling. In this paper, we first propose a simple extension of sentence-level early-exit for sequence labeling tasks. To further reduce the computational cost, we also propose a token-level early-exit mechanism that allows partial tokens to exit early at different layers. Considering the local dependency inherent in sequence labeling, we employed a window-based criterion to decide for a token whether or not to exit. The token-level early-exit brings the gap between training and inference, so we introduce an extra self-sampling fine-tuning stage to alleviate it. The extensive experiments on three popular sequence labeling tasks show that our approach can save up to 66%-75% inference cost with minimal performance degradation. Compared with competitive compressed models such as DistilBERT, our approach can achieve better performance under the same speed-up ratios of 2X, 3X, and 4X.