 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract then Distill: Efficient and Effective Task-Agnostic BERT Distillation
Paper and Code
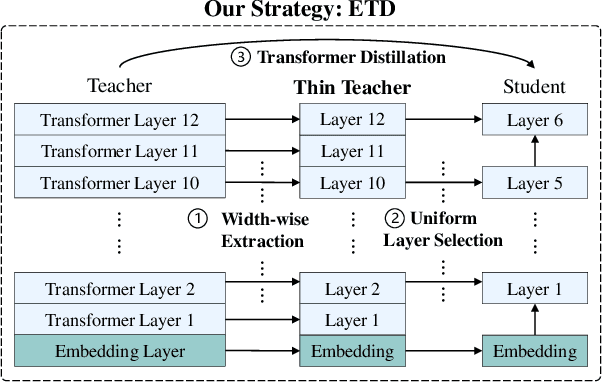
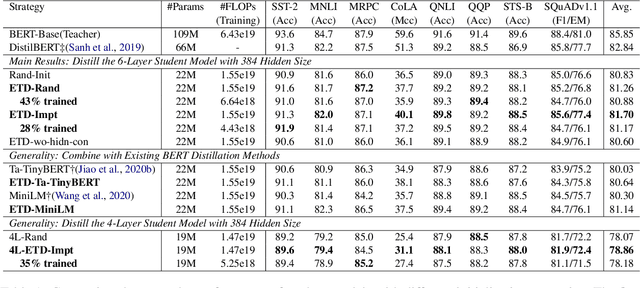
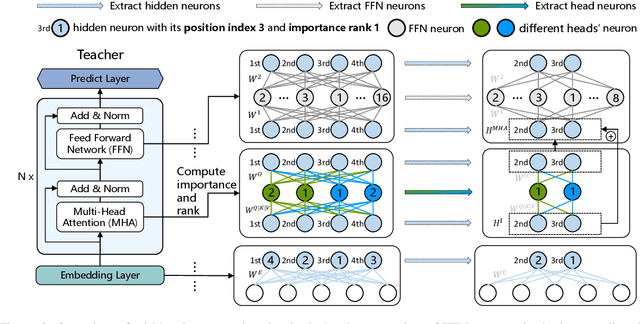
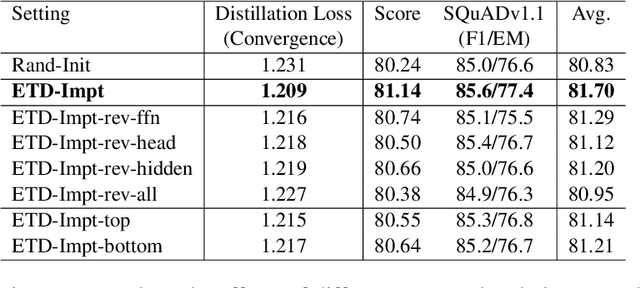
Task-agnostic knowledge distillation, a teacher-student framework, has been proved effective for BERT compression. Although achieving promising results on NLP tasks, it requires enormous computational resources. In this paper, we propose Extract Then Distill (ETD), a generic and flexible strategy to reuse the teacher's parameters for efficient and effective task-agnostic distillation, which can be applied to students of any size. Specifically, we introduce two variants of ETD, ETD-Rand and ETD-Impt, which extract the teacher's parameters in a random manner and by following an importance metric respectively. In this way, the student has already acquired some knowledge at the beginning of the distillation process, which makes the distillation process converge faster. We demonstrate the effectiveness of ETD on the GLUE benchmark and SQuAD. The experimental results show that: (1) compared with the baseline without an ETD strategy, ETD can save 70\% of computation cost. Moreover, it achieves better results than the baseline when using the same computing resource. (2) ETD is generic and has been proven effective for different distillation methods (e.g., TinyBERT and MiniLM) and students of different sizes. The source code will be publicly available upon publication.