 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation
Paper and Code
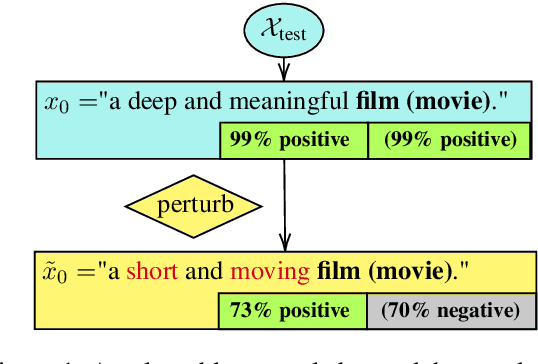

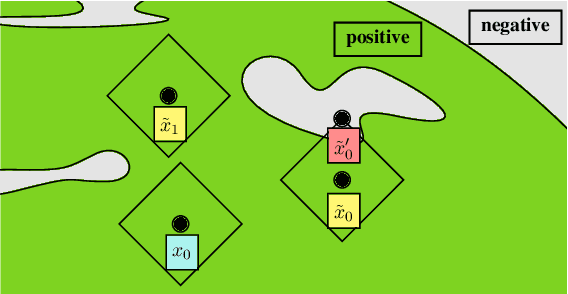
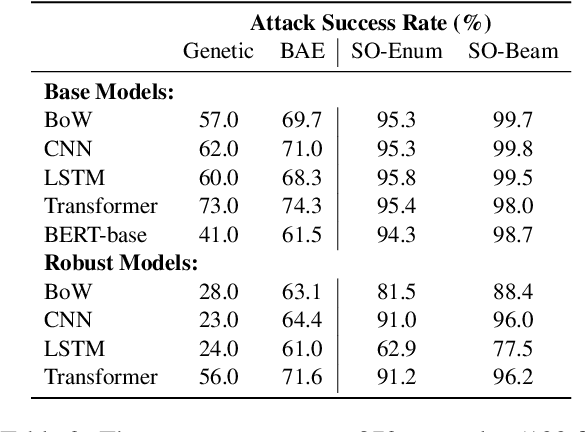
Robustness and counterfactual bias are usually evaluated on a test dataset. However, are these evaluations robust? If the test dataset is perturbed slightly, will the evaluation results keep the same? In this paper, we propose a "double perturbation" framework to uncover model weaknesses beyond the test dataset. The framework first perturbs the test dataset to construct abundant natural sentences similar to the test data, and then diagnoses the prediction change regarding a single-word substitution. We apply this framework to study two perturbation-based approaches that are used to analyze models' robustness and counterfactual bias in English. (1) For robustness, we focus on synonym substitutions and identify vulnerable examples where prediction can be altered. Our proposed attack attains high success rates (96.0%-99.8%) in finding vulnerable examples on both original and robustly trained CNNs and Transformers. (2) For counterfactual bias, we focus on substituting demographic tokens (e.g., gender, race) and measure the shift of the expected prediction among constructed sentences. Our method is able to reveal the hidden model biases not directly shown in the test dataset. Our code is available at https://github.com/chong-z/nlp-second-order-attack.