Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgespeechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment
Paper and Code
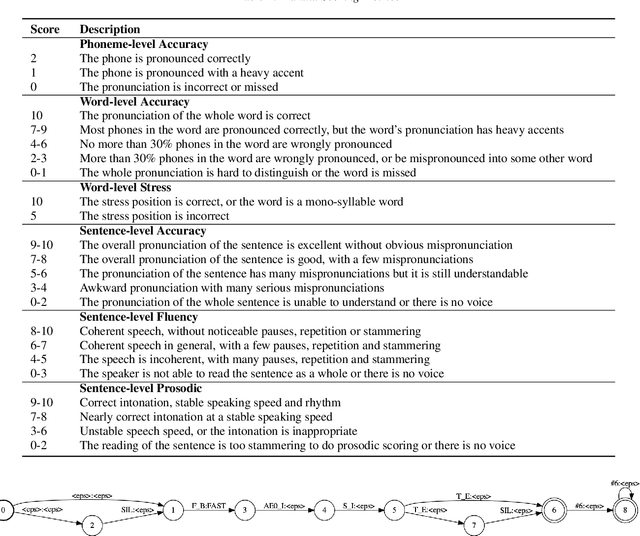
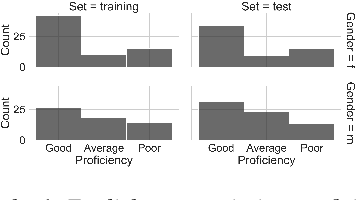

This paper introduces a new open-source speech corpus named "speechocean762" designed for pronunciation assessment use, consisting of 5000 English utterances from 250 non-native speakers, where half of the speakers are children. Five experts annotated each of the utterances at sentence-level, word-level and phoneme-level. A baseline system is released in open source to illustrate the phoneme-level pronunciation assessment workflow on this corpus. This corpus is allowed to be used freely for commercial and non-commercial purposes. It is available for free download from OpenSLR, and the corresponding baseline system is published in the Kaldi speech recognition toolkit.
View paper on