 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Learning Prosodic-Enhanced Representation of Rap Lyrics
Paper and Code
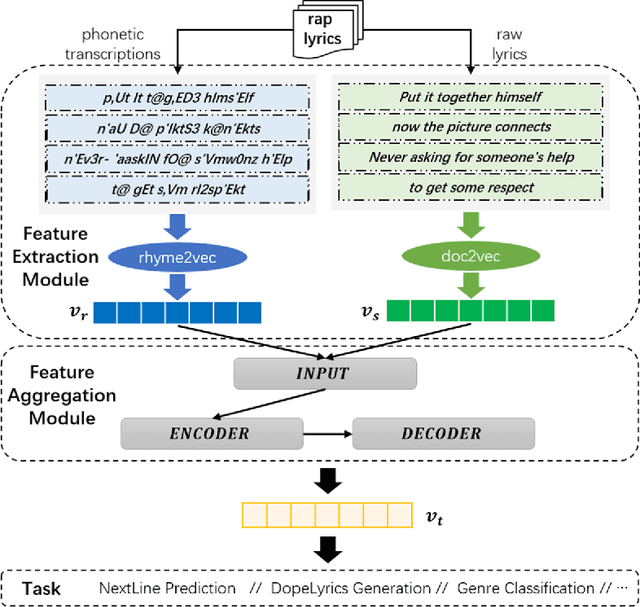


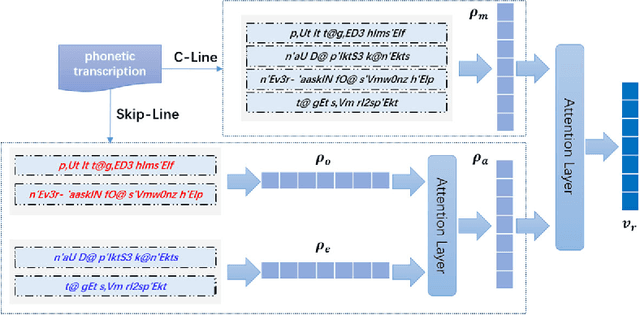
Learning and analyzing rap lyrics is a significant basis for many web applications, such as music recommendation, automatic music categorization, and music information retrieval, due to the abundant source of digital music in the World Wide Web. Although numerous studies have explored the topic, knowledge in this field is far from satisfactory, because critical issues, such as prosodic information and its effective representation, as well as appropriate integration of various features, are usually ignored. In this paper, we propose a hierarchical attention variational autoencoder framework (HAVAE), which simultaneously consider semantic and prosodic features for rap lyrics representation learning. Specifically, the representation of the prosodic features is encoded by phonetic transcriptions with a novel and effective strategy~(i.e., rhyme2vec). Moreover, a feature aggregation strategy is proposed to appropriately integrate various features and generate prosodic-enhanced representation. A comprehensive empirical evaluation demonstrates that the proposed framework outperforms the state-of-the-art approaches under various metrics in different rap lyrics learning tasks.