 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlonD: An Automatic Evaluation Metric for Document-level MachineTranslation
Paper and Code

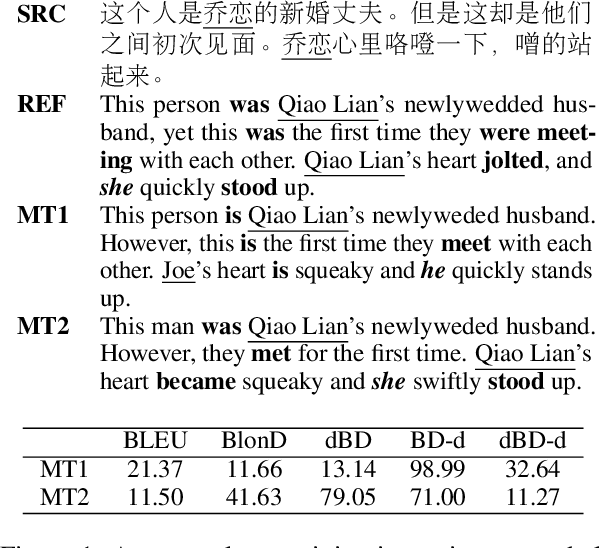
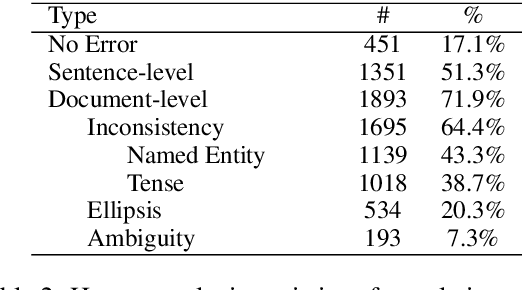
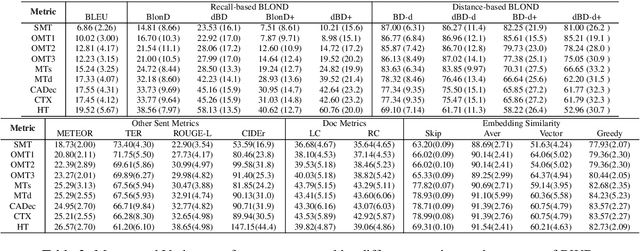
Standard automatic metrics (such as BLEU) are problematic for document-level MT evaluation. They can neither distinguish document-level improvements in translation quality from sentence-level ones nor can they identify the specific discourse phenomena that caused the translation errors. To address these problems, we propose an automatic metric BlonD for document-level machine translation evaluation. BlonD takes discourse coherence into consideration by calculating the recall and distance of check-pointing phrases and tags, and further provides comprehensive evaluation scores by combining with n-gram. Extensive comparisons between BlonD and existing evaluation metrics are conducted to illustrate their critical distinctions. Experimental results show that BlonD has a much higher document-level sensitivity with respect to previous metrics. The human evaluation also reveals high Pearson R correlation values between BlonD scores and manual quality judgments.