 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-book Video Captioning with Retrieve-Copy-Generate Network
Paper and Code
Mar 09, 2021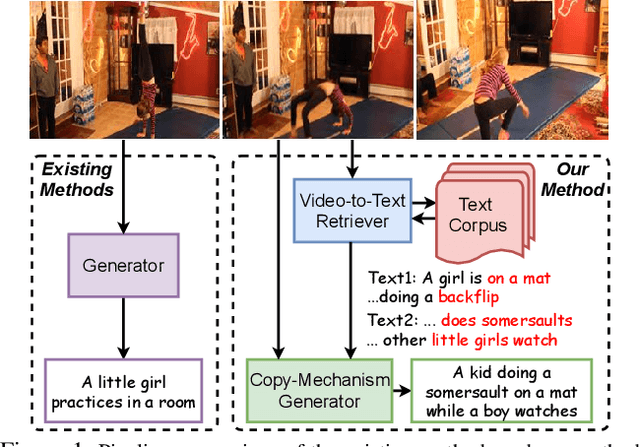
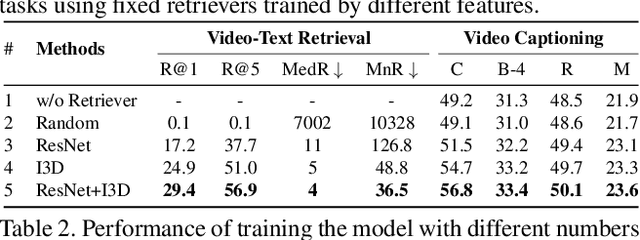
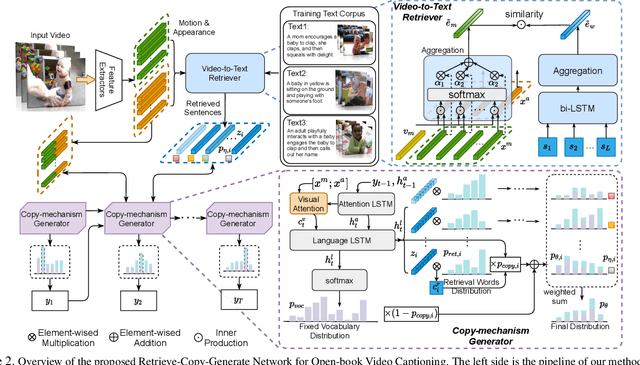
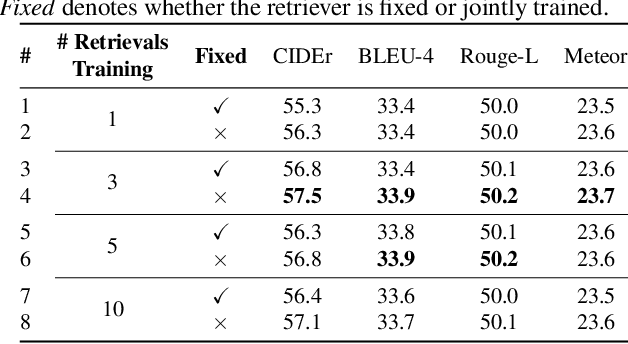
Due to the rapid emergence of short videos and the requirement for content understanding and creation, the video captioning task has received increasing attention in recent years. In this paper, we convert traditional video captioning task into a new paradigm, \ie, Open-book Video Captioning, which generates natural language under the prompts of video-content-relevant sentences, not limited to the video itself. To address the open-book video captioning problem, we propose a novel Retrieve-Copy-Generate network, where a pluggable video-to-text retriever is constructed to retrieve sentences as hints from the training corpus effectively, and a copy-mechanism generator is introduced to extract expressions from multi-retrieved sentences dynamically. The two modules can be trained end-to-end or separately, which is flexible and extensible. Our framework coordinates the conventional retrieval-based methods with orthodox encoder-decoder methods, which can not only draw on the diverse expressions in the retrieved sentences but also generate natural and accurate content of the video. Extensive experiments on several benchmark datasets show that our proposed approach surpasses the state-of-the-art performance, indicating the effectiveness and promising of the proposed paradigm in the task of video captioning.