 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition
Paper and Code
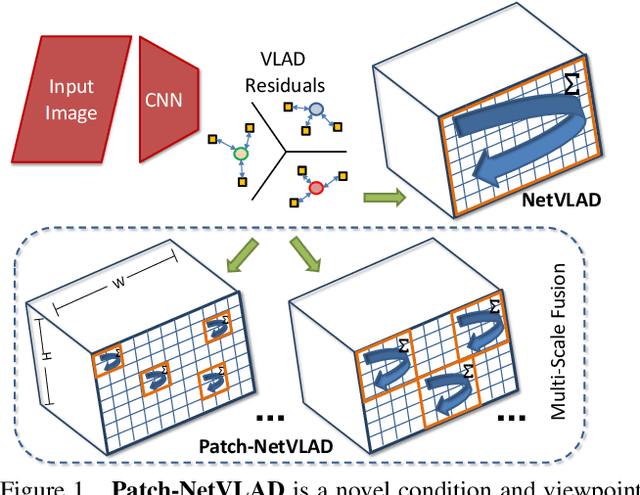
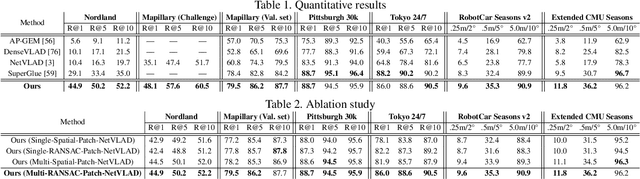
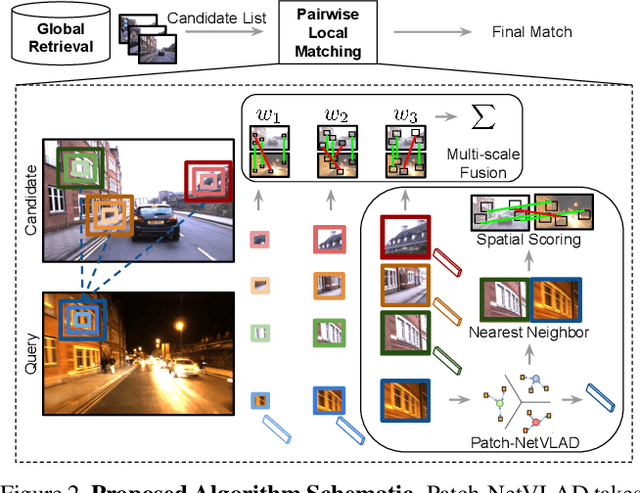
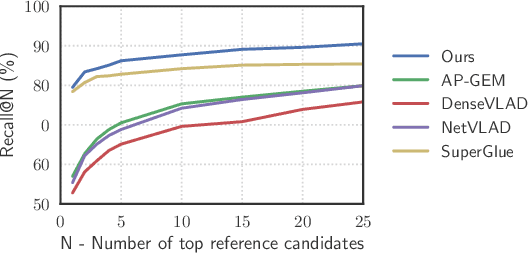
Visual Place Recognition is a challenging task for robotics and autonomous systems, which must deal with the twin problems of appearance and viewpoint change in an always changing world. This paper introduces Patch-NetVLAD, which provides a novel formulation for combining the advantages of both local and global descriptor methods by deriving patch-level features from NetVLAD residuals. Unlike the fixed spatial neighborhood regime of existing local keypoint features, our method enables aggregation and matching of deep-learned local features defined over the feature-space grid. We further introduce a multi-scale fusion of patch features that have complementary scales (i.e. patch sizes) via an integral feature space and show that the fused features are highly invariant to both condition (season, structure, and illumination) and viewpoint (translation and rotation) changes. Patch-NetVLAD outperforms both global and local feature descriptor-based methods with comparable compute, achieving state-of-the-art visual place recognition results on a range of challenging real-world datasets, including winning the Facebook Mapillary Visual Place Recognition Challenge at ECCV2020. It is also adaptable to user requirements, with a speed-optimised version operating over an order of magnitude faster than the state-of-the-art. By combining superior performance with improved computational efficiency in a configurable framework, Patch-NetVLAD is well suited to enhance both stand-alone place recognition capabilities and the overall performance of SLAM systems.