 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Language Priors with Self-supervised Learning for Visual Question Answering
Paper and Code
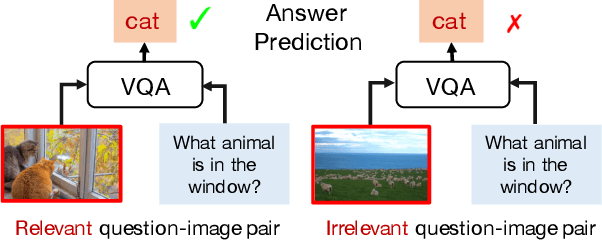
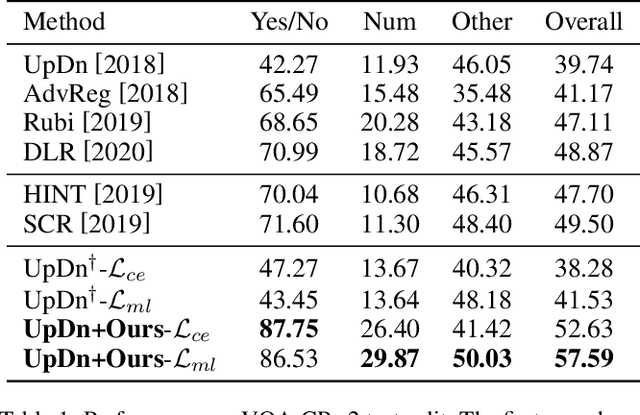
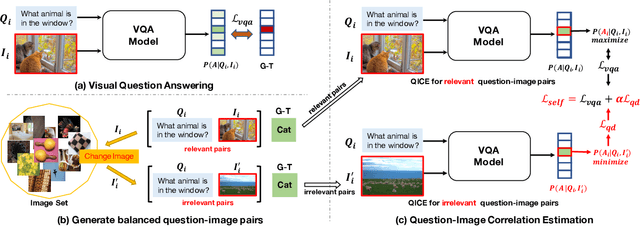
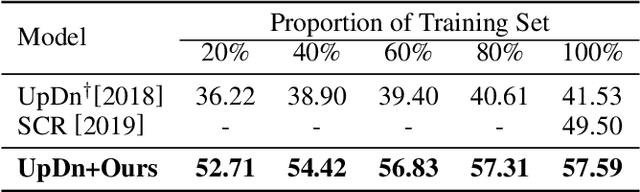
Most Visual Question Answering (VQA) models suffer from the language prior problem, which is caused by inherent data biases. Specifically, VQA models tend to answer questions (e.g., what color is the banana?) based on the high-frequency answers (e.g., yellow) ignoring image contents. Existing approaches tackle this problem by creating delicate models or introducing additional visual annotations to reduce question dependency while strengthening image dependency. However, they are still subject to the language prior problem since the data biases have not been even alleviated. In this paper, we introduce a self-supervised learning framework to solve this problem. Concretely, we first automatically generate labeled data to balance the biased data, and propose a self-supervised auxiliary task to utilize the balanced data to assist the base VQA model to overcome language priors. Our method can compensate for the data biases by generating balanced data without introducing external annotations. Experimental results show that our method can significantly outperform the state-of-the-art, improving the overall accuracy from 49.50% to 57.59% on the most commonly used benchmark VQA-CP v2. In other words, we can increase the performance of annotation-based methods by 16% without using external annotations.