 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Layout Manipulation with High-Resolution Sparse Attention
Paper and Code
Dec 14, 2020
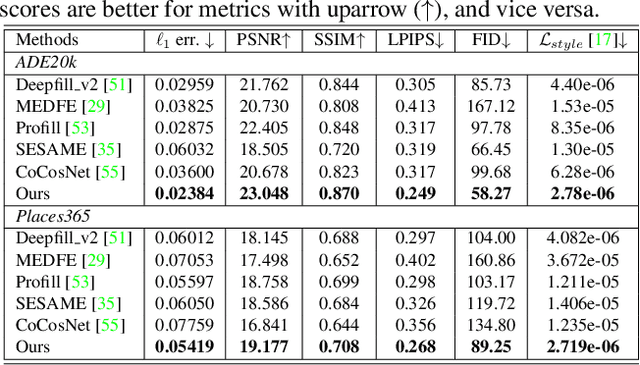
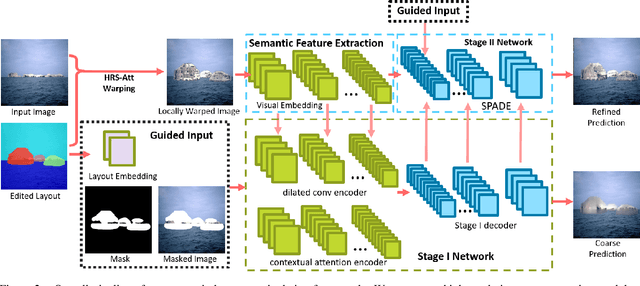
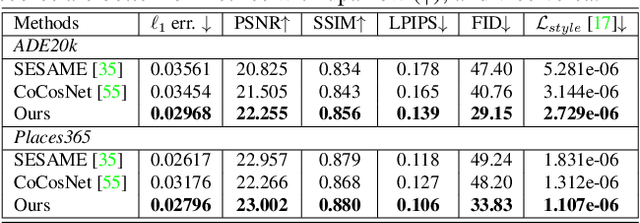
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.