 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDAF: Top-Down Attention Framework for Vision Tasks
Paper and Code
Dec 14, 2020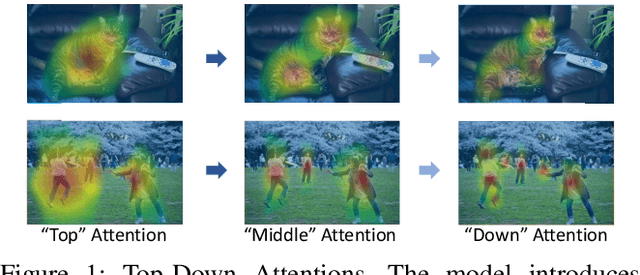
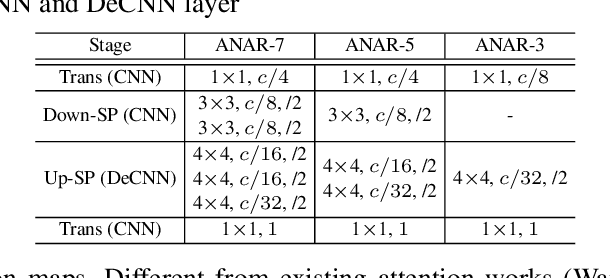
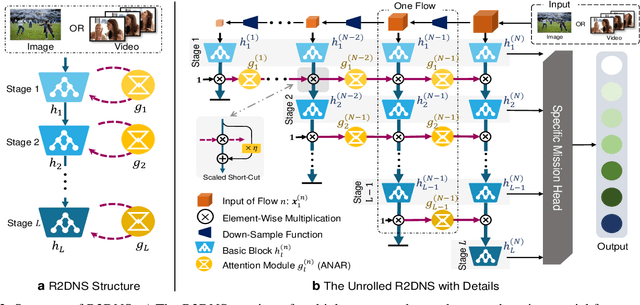
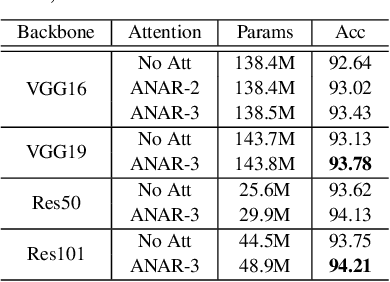
Human attention mechanisms often work in a top-down manner, yet it is not well explored in vision research. Here, we propose the Top-Down Attention Framework (TDAF) to capture top-down attentions, which can be easily adopted in most existing models. The designed Recursive Dual-Directional Nested Structure in it forms two sets of orthogonal paths, recursive and structural ones, where bottom-up spatial features and top-down attention features are extracted respectively. Such spatial and attention features are nested deeply, therefore, the proposed framework works in a mixed top-down and bottom-up manner. Empirical evidence shows that our TDAF can capture effective stratified attention information and boost performance. ResNet with TDAF achieves 2.0% improvements on ImageNet. For object detection, the performance is improved by 2.7% AP over FCOS. For pose estimation, TDAF improves the baseline by 1.6%. And for action recognition, the 3D-ResNet adopting TDAF achieves improvements of 1.7% accuracy.