 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitNet: Divide and Co-training
Paper and Code
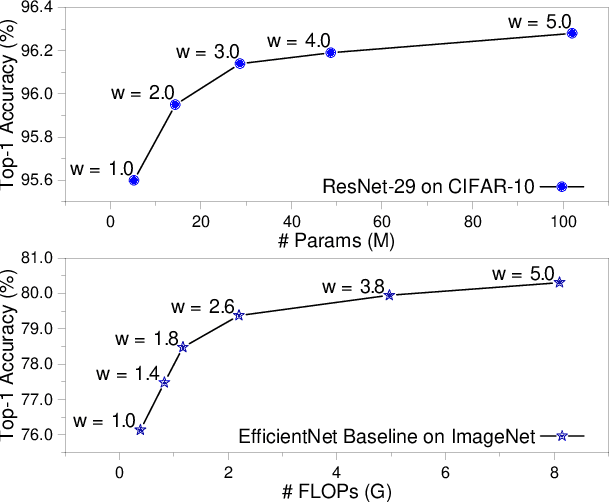

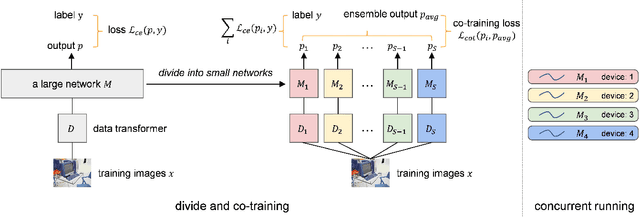
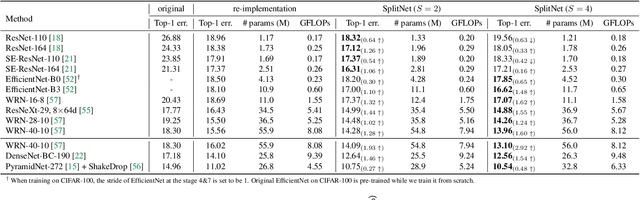
The width of a neural network matters since increasing the width will necessarily increase the model capacity. However, the performance of a network does not improve linearly with the width and soon gets saturated. To tackle this problem, we propose to increase the number of networks rather than purely scaling up the width. To prove it, one large network is divided into several small ones, and each of these small networks has a fraction of the original one's parameters. We then train these small networks together and make them see various views of the same data to learn different and complementary knowledge. During this co-training process, networks can also learn from each other. As a result, small networks can achieve better ensemble performance than the large one with few or no extra parameters or FLOPs. \emph{This reveals that the number of networks is a new dimension of effective model scaling, besides depth/width/resolution}. Small networks can also achieve faster inference speed than the large one by concurrent running on different devices. We validate the idea -- increasing the number of networks is a new dimension of effective model scaling -- with different network architectures on common benchmarks through extensive experiments. The code is available at \url{https://github.com/mzhaoshuai/SplitNet-Divide-and-Co-training}.