 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network iLQR: A New Reinforcement Learning Architecture
Paper and Code
Nov 21, 2020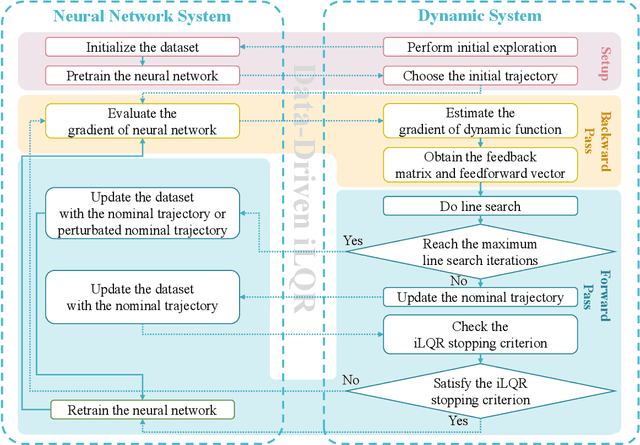
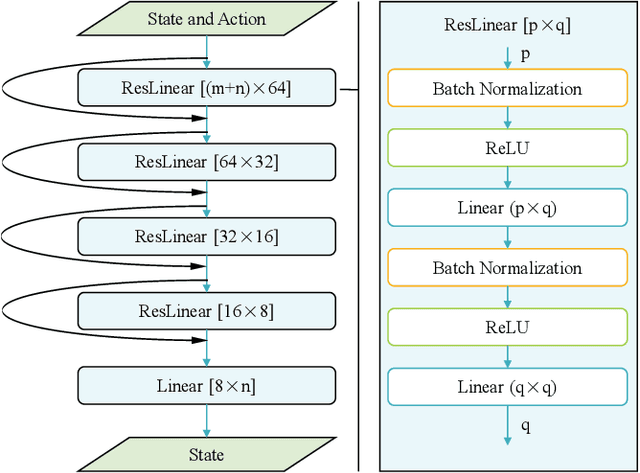
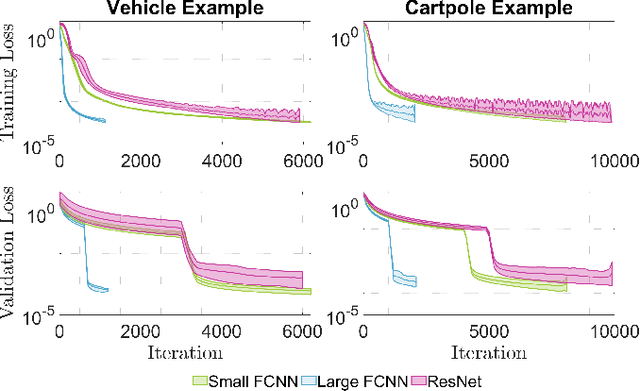
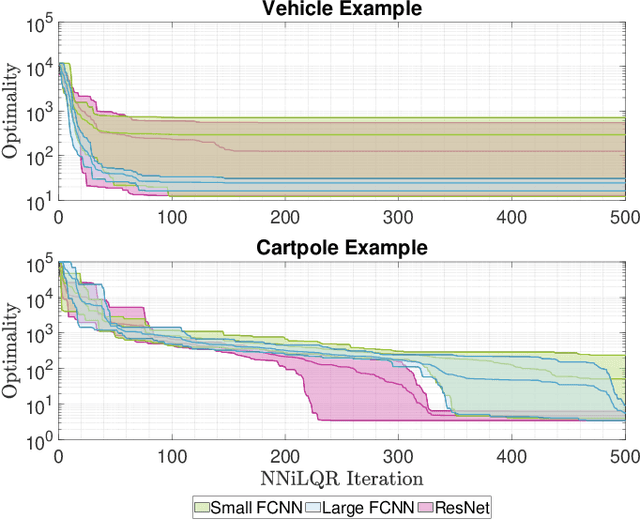
As a notable machine learning paradigm, the research efforts in the context of reinforcement learning have certainly progressed leaps and bounds. When compared with reinforcement learning methods with the given system model, the methodology of the reinforcement learning architecture based on the unknown model generally exhibits significantly broader universality and applicability. In this work, a new reinforcement learning architecture is developed and presented without the requirement of any prior knowledge of the system model, which is termed as an approach of a "neural network iterative linear quadratic regulator (NNiLQR)". Depending solely on measurement data, this method yields a completely new non-parametric routine for the establishment of the optimal policy (without the necessity of system modeling) through iterative refinements of the neural network system. Rather importantly, this approach significantly outperforms the classical iterative linear quadratic regulator (iLQR) method in terms of the given objective function because of the innovative utilization of further exploration in the methodology. As clearly indicated from the results attained in two illustrative examples, these significant merits of the NNiLQR method are demonstrated rather evidently.