 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Prosody Modelling with Cross-Utterance BERT Embeddings for End-to-end Speech Synthesis
Paper and Code
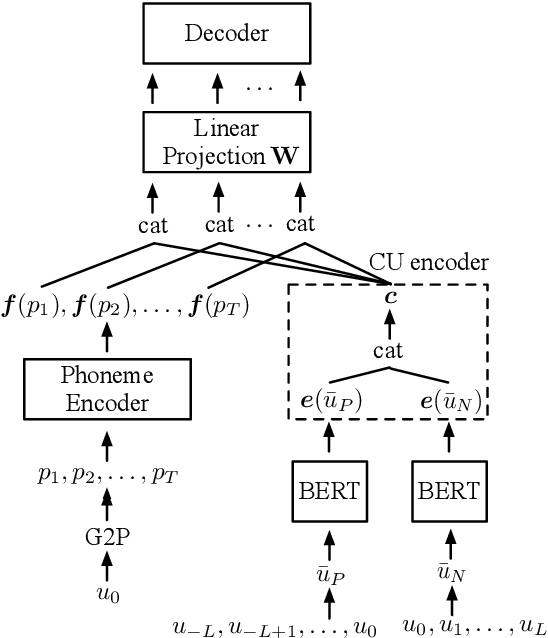
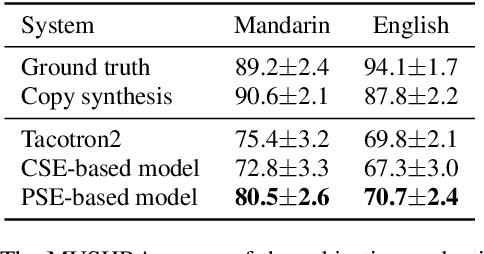
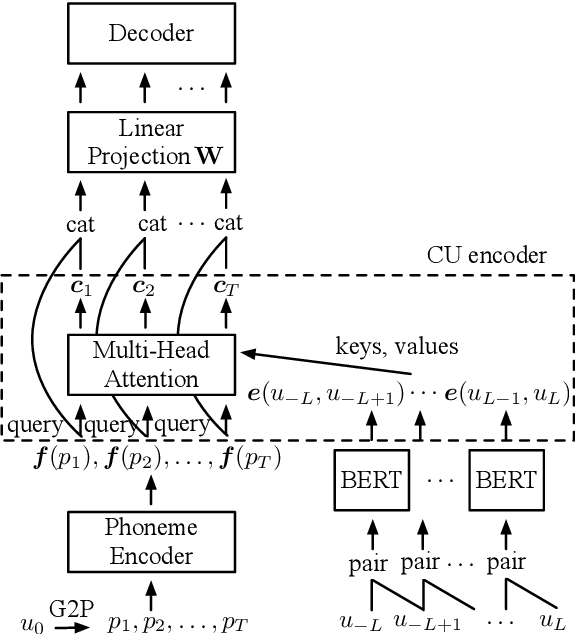
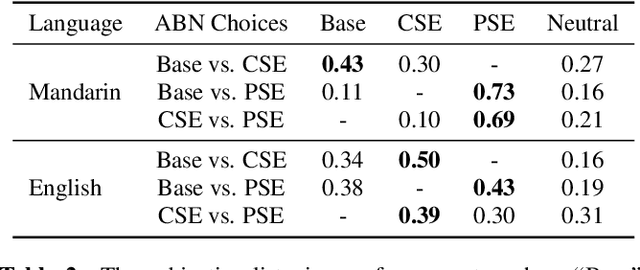
Despite prosody is related to the linguistic information up to the discourse structure, most text-to-speech (TTS) systems only take into account that within each sentence, which makes it challenging when converting a paragraph of texts into natural and expressive speech. In this paper, we propose to use the text embeddings of the neighboring sentences to improve the prosody generation for each utterance of a paragraph in an end-to-end fashion without using any explicit prosody features. More specifically, cross-utterance (CU) context vectors, which are produced by an additional CU encoder based on the sentence embeddings extracted by a pre-trained BERT model, are used to augment the input of the Tacotron2 decoder. Two types of BERT embeddings are investigated, which leads to the use of different CU encoder structures. Experimental results on a Mandarin audiobook dataset and the LJ-Speech English audiobook dataset demonstrate the use of CU information can improve the naturalness and expressiveness of the synthesized speech. Subjective listening testing shows most of the participants prefer the voice generated using the CU encoder over that generated using standard Tacotron2. It is also found that the prosody can be controlled indirectly by changing the neighbouring sentences.