 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheck-N-Run: A Checkpointing System for Training Recommendation Models
Paper and Code
Oct 17, 2020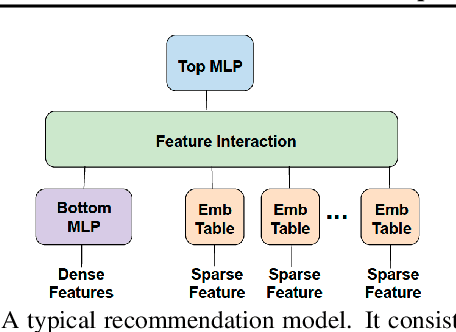
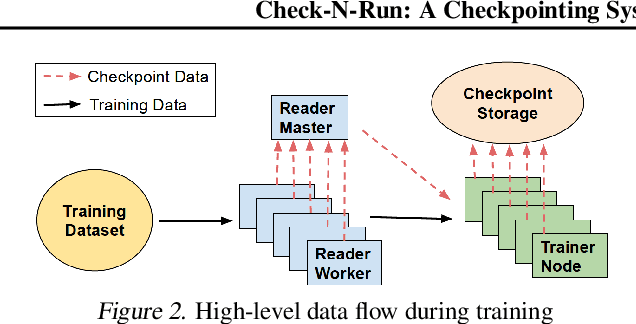
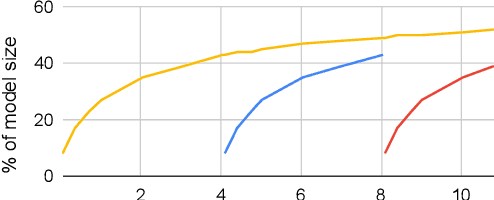
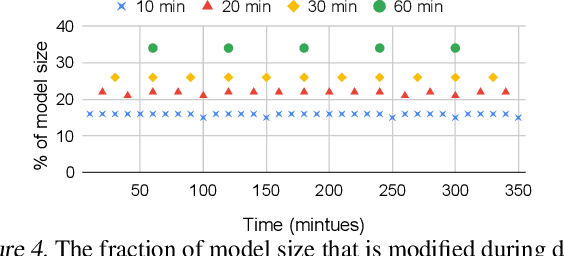
Checkpoints play an important role in training recommendation systems at scale. They are important for many use cases, including failure recovery to ensure rapid training progress, and online training to improve inference prediction accuracy. Checkpoints are typically written to remote, persistent storage. Given the typically large and ever-increasing recommendation model sizes, the checkpoint frequency and effectiveness is often bottlenecked by the storage write bandwidth and capacity, as well as the network bandwidth. We present Check-N-Run, a scalable checkpointing system for training large recommendation models. Check-N-Run uses two primary approaches to address these challenges. First, it applies incremental checkpointing, which tracks and checkpoints the modified part of the model. On top of that, it leverages quantization techniques to significantly reduce the checkpoint size, without degrading training accuracy. These techniques allow Check-N-Run to reduce the required write bandwidth by 6-17x and the required capacity by 2.5-8x on real-world models at Facebook, and thereby significantly improve checkpoint capabilities while reducing the total cost of ownership.