 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Knowledge Distillation
Paper and Code

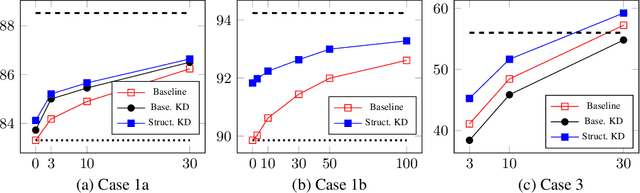
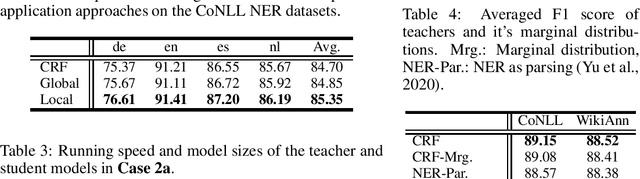
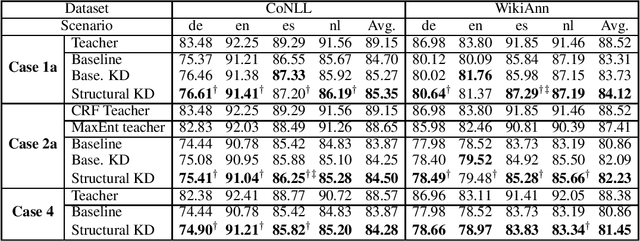
Knowledge distillation is a critical technique to transfer knowledge between models, typically from a large model (the teacher) to a smaller one (the student). The objective function of knowledge distillation is typically the cross-entropy between the teacher and the student's output distributions. However, for structured prediction problems, the output space is exponential in size; therefore, the cross-entropy objective becomes intractable to compute and optimize directly. In this paper, we derive a factorized form of the knowledge distillation objective for structured prediction, which is tractable for many typical choices of the teacher and student models. In particular, we show the tractability and empirical effectiveness of structural knowledge distillation between sequence labeling and dependency parsing models under four different scenarios: 1) the teacher and student share the same factorization form of the output structure scoring function; 2) the student factorization produces smaller substructures than the teacher factorization; 3) the teacher factorization produces smaller substructures than the student factorization; 4) the factorization forms from the teacher and the student are incompatible.