 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Filter in Filter
Paper and Code

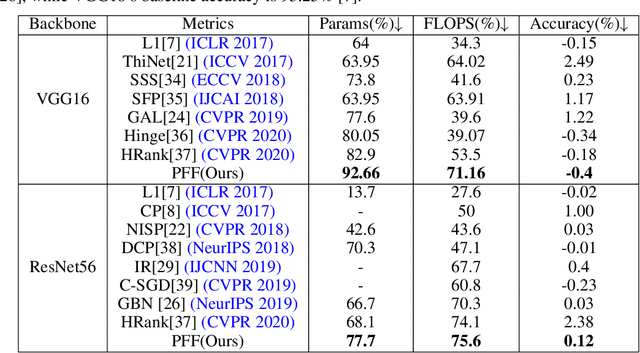
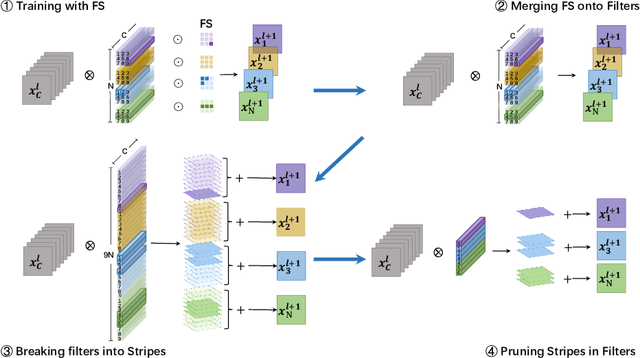
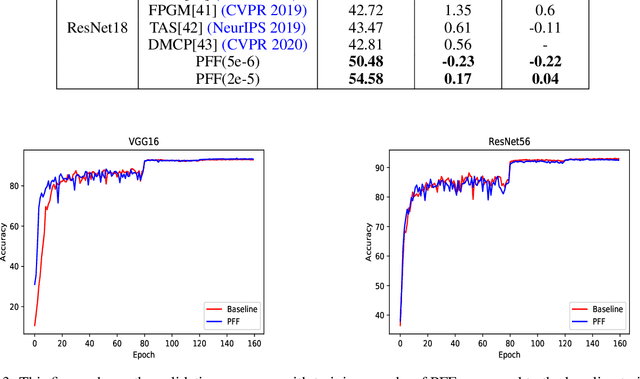
Pruning has become a very powerful and effective technique to compress and accelerate modern neural networks. Existing pruning methods can be grouped into two categories: filter pruning (FP) and weight pruning (WP). FP wins at hardware compatibility but loses at the compression ratio compared with WP. To converge the strength of both methods, we propose to prune the filter in the filter. Specifically, we treat a filter $F \in \mathbb{R}^{C\times K\times K}$ as $K \times K$ stripes, \emph{i.e.}, $1\times 1$ filters $\in \mathbb{R}^{C}$, then by pruning the stripes instead of the whole filter, we can achieve finer granularity than traditional FP while being hardware friendly. We term our method as SWP (\emph{Stripe-Wise Pruning}). SWP is implemented by introducing a novel learnable matrix called Filter Skeleton, whose values reflect the shape of each filter. As some recent work has shown that the pruned architecture is more crucial than the inherited important weights, we argue that the architecture of a single filter, \emph{i.e.}, the shape, also matters. Through extensive experiments, we demonstrate that SWP is more effective compared to the previous FP-based methods and achieves the state-of-art pruning ratio on CIFAR-10 and ImageNet datasets without obvious accuracy drop. Code is available at https://github.com/fxmeng/Pruning-Filter-in-Filter