 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Distillation on Intermediate Representations for Language Model Compression
Paper and Code
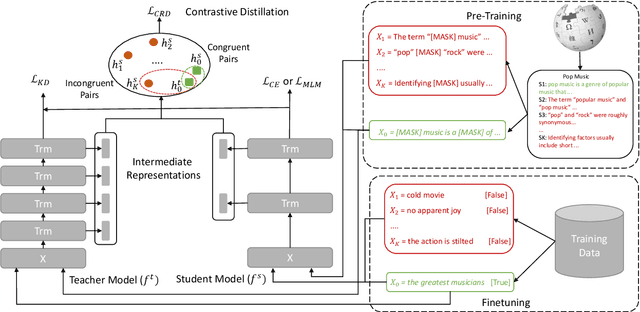
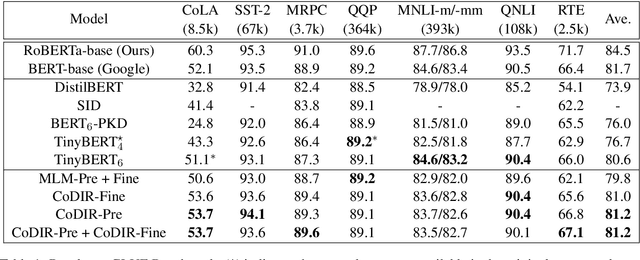
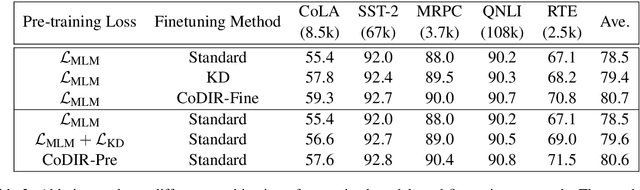

Existing language model compression methods mostly use a simple L2 loss to distill knowledge in the intermediate representations of a large BERT model to a smaller one. Although widely used, this objective by design assumes that all the dimensions of hidden representations are independent, failing to capture important structural knowledge in the intermediate layers of the teacher network. To achieve better distillation efficacy, we propose Contrastive Distillation on Intermediate Representations (CoDIR), a principled knowledge distillation framework where the student is trained to distill knowledge through intermediate layers of the teacher via a contrastive objective. By learning to distinguish positive sample from a large set of negative samples, CoDIR facilitates the student's exploitation of rich information in teacher's hidden layers. CoDIR can be readily applied to compress large-scale language models in both pre-training and finetuning stages, and achieves superb performance on the GLUE benchmark, outperforming state-of-the-art compression methods.