 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSP: An FPGA-Specific Mixed-Scheme, Multi-Precision Deep Neural Network Quantization Framework
Paper and Code
Sep 16, 2020
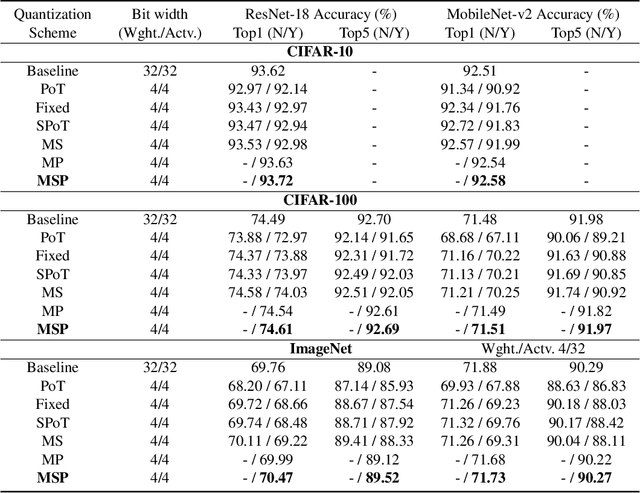
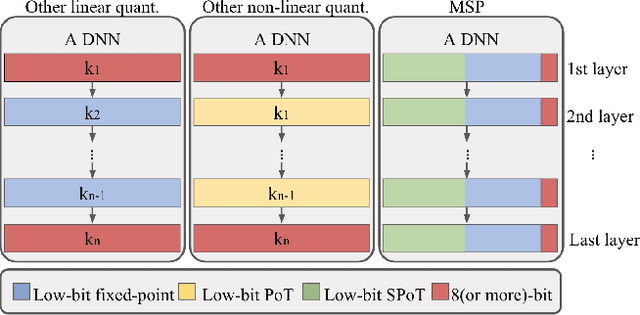
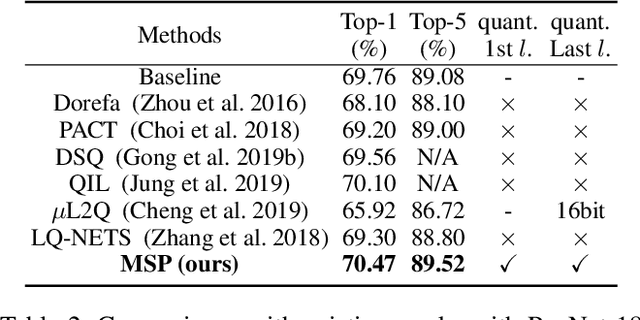
With the tremendous success of deep learning, there exists imminent need to deploy deep learning models onto edge devices. To tackle the limited computing and storage resources in edge devices, model compression techniques have been widely used to trim deep neural network (DNN) models for on-device inference execution. This paper targets the commonly used FPGA (field programmable gate array) devices as the hardware platforms for DNN edge computing. We focus on the DNN quantization as the main model compression technique, since DNN quantization has been of great importance for the implementations of DNN models on the hardware platforms. The novelty of this work comes in twofold: (i) We propose a mixed-scheme DNN quantization method that incorporates both the linear and non-linear number systems for quantization, with the aim to boost the utilization of the heterogeneous computing resources, i.e., LUTs (look up tables) and DSPs (digital signal processors) on an FPGA. Note that all the existing (single-scheme) quantization methods can only utilize one type of resources (either LUTs or DSPs for the MAC (multiply-accumulate) operations in deep learning computations. (ii) We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach.