 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Fine-tuning Pre-trained Models Lead to Perfect NLP? A Study of the Generalizability of Relation Extraction
Paper and Code

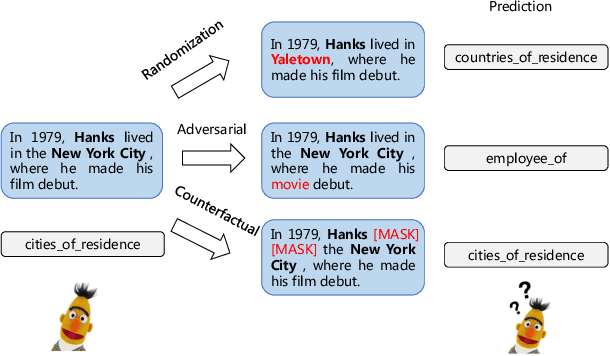
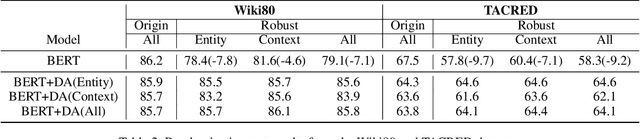
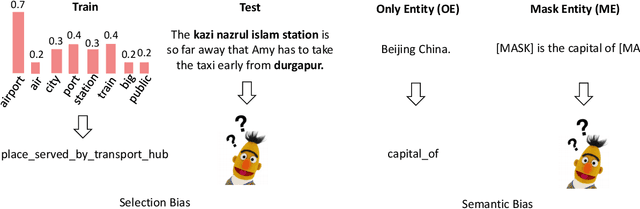
Fine-tuning pre-trained models have achieved impressive performance on standard natural language processing benchmarks. However, the resultant model generalizability remains poorly understood. We do not know, for example, how excellent performance can lead to the perfection of generalization models. In this study, we analyze a fine-tuned BERT model from different perspectives using relation extraction. We also characterize the differences in generalization techniques according to our proposed improvements. From empirical experimentation, we find that BERT suffers a bottleneck in terms of robustness by way of randomizations, adversarial and counterfactual tests, and biases (i.e., selection and semantic). These findings highlight opportunities for future improvements. Our open-sourced testbed DiagnoseRE is available in https://github.com/zjunlp/DiagnoseRE/.