 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overview of Deep-Learning-Based Audio-Visual Speech Enhancement and Separation
Paper and Code
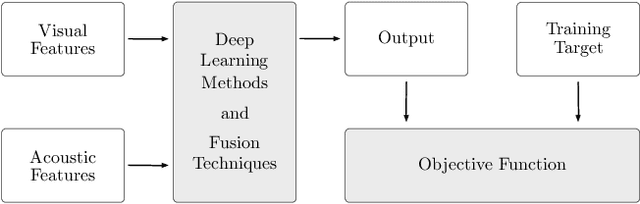
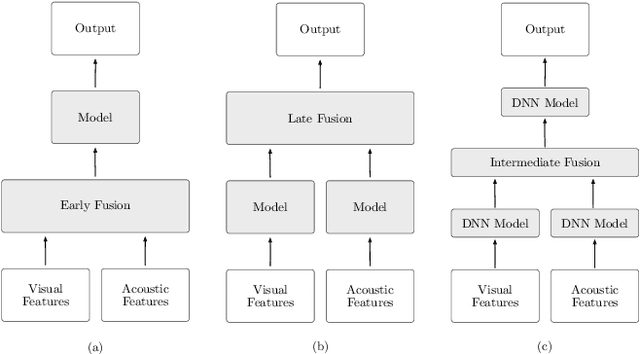
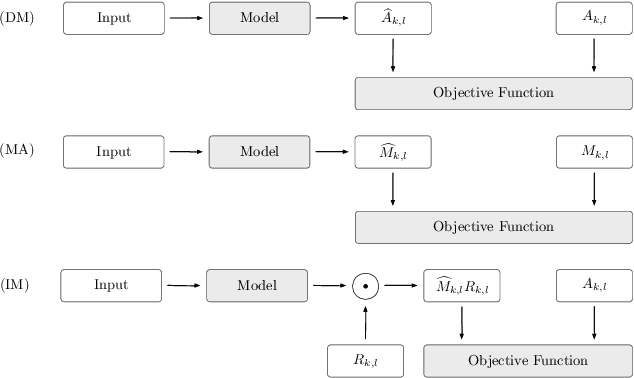
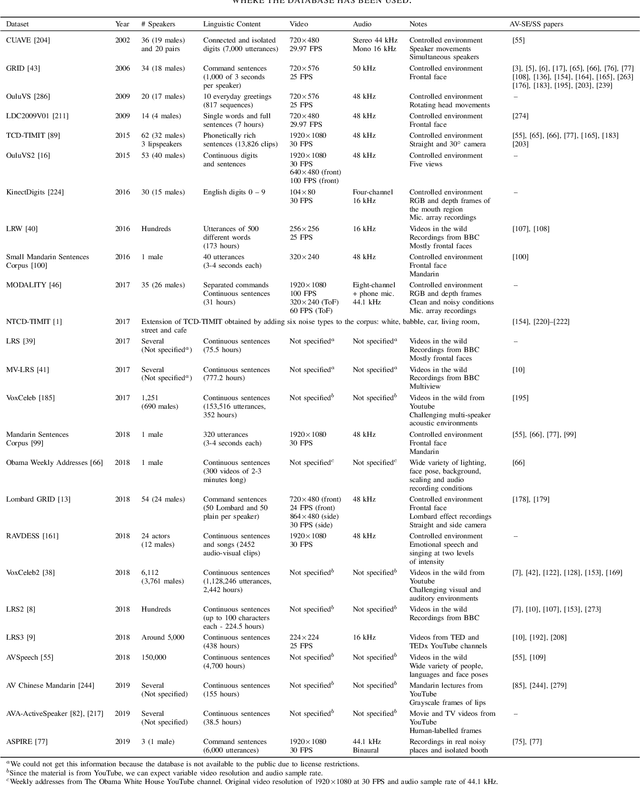
Speech enhancement and speech separation are two related tasks, whose purpose is to extract either one or more target speech signals, respectively, from a mixture of sounds generated by several sources. Traditionally, these tasks have been tackled using signal processing and machine learning techniques applied to the available acoustic signals. More recently, visual information from the target speakers, such as lip movements and facial expressions, has been introduced to speech enhancement and speech separation systems, because the visual aspect of speech is essentially unaffected by the acoustic environment. In order to efficiently fuse acoustic and visual information, researchers have exploited the flexibility of data-driven approaches, specifically deep learning, achieving state-of-the-art performance. The ceaseless proposal of a large number of techniques to extract features and fuse multimodal information has highlighted the need for an overview that comprehensively describes and discusses audio-visual speech enhancement and separation based on deep learning. In this paper, we provide a systematic survey of this research topic, focusing on the main elements that characterise the systems in the literature: visual features; acoustic features; deep learning methods; fusion techniques; training targets and objective functions. We also survey commonly employed audio-visual speech datasets, given their central role in the development of data-driven approaches, and evaluation methods, because they are generally used to compare different systems and determine their performance. In addition, we review deep-learning-based methods for speech reconstruction from silent videos and audio-visual sound source separation for non-speech signals, since these methods can be more or less directly applied to audio-visual speech enhancement and separation.