 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSinger: Singing Voice Synthesis with Data Mined From the Web
Paper and Code

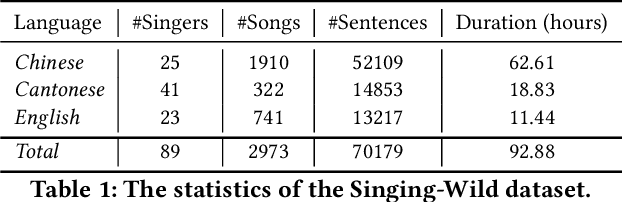
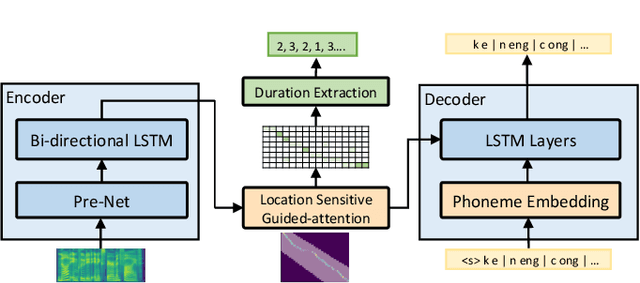

In this paper, we develop DeepSinger, a multi-lingual multi-singer singing voice synthesis (SVS) system, which is built from scratch using singing training data mined from music websites. The pipeline of DeepSinger consists of several steps, including data crawling, singing and accompaniment separation, lyrics-to-singing alignment, data filtration, and singing modeling. Specifically, we design a lyrics-to-singing alignment model to automatically extract the duration of each phoneme in lyrics starting from coarse-grained sentence level to fine-grained phoneme level, and further design a multi-lingual multi-singer singing model based on a feed-forward Transformer to directly generate linear-spectrograms from lyrics, and synthesize voices using Griffin-Lim. DeepSinger has several advantages over previous SVS systems: 1) to the best of our knowledge, it is the first SVS system that directly mines training data from music websites, 2) the lyrics-to-singing alignment model further avoids any human efforts for alignment labeling and greatly reduces labeling cost, 3) the singing model based on a feed-forward Transformer is simple and efficient, by removing the complicated acoustic feature modeling in parametric synthesis and leveraging a reference encoder to capture the timbre of a singer from noisy singing data, and 4) it can synthesize singing voices in multiple languages and multiple singers. We evaluate DeepSinger on our mined singing dataset that consists of about 92 hours data from 89 singers on three languages (Chinese, Cantonese and English). The results demonstrate that with the singing data purely mined from the Web, DeepSinger can synthesize high-quality singing voices in terms of both pitch accuracy and voice naturalness (footnote: Our audio samples are shown in https://speechresearch.github.io/deepsinger/.)