 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sampling-Based Maximum Entropy Inverse Reinforcement Learning with Application to Autonomous Driving
Paper and Code
Jun 22, 2020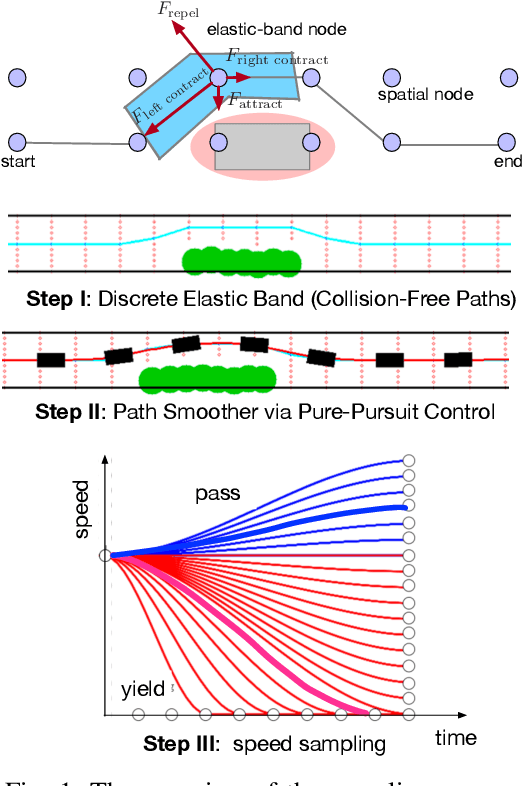
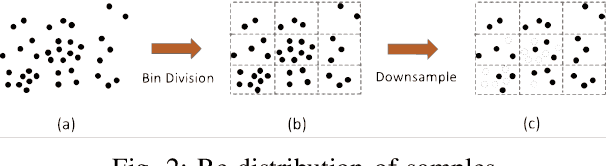
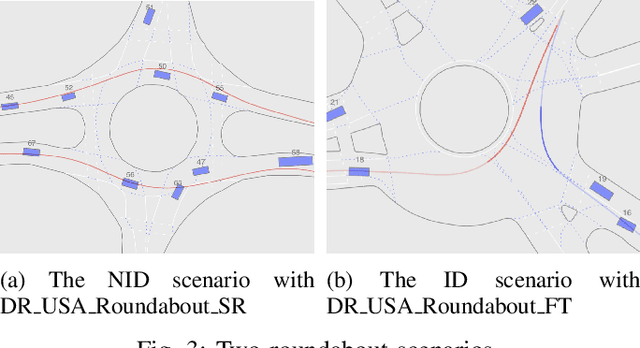
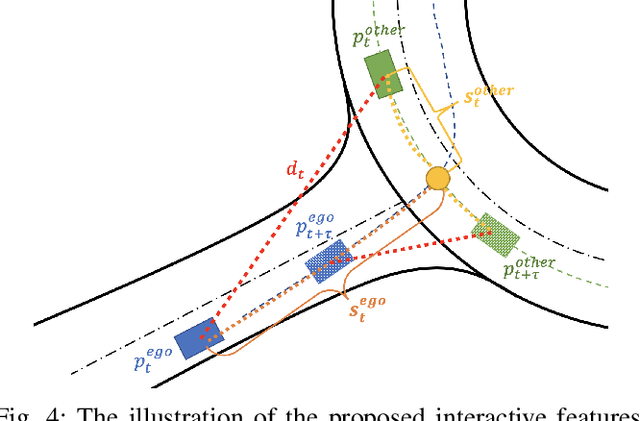
In the past decades, we have witnessed significant progress in the domain of autonomous driving. Advanced techniques based on optimization and reinforcement learning (RL) become increasingly powerful at solving the forward problem: given designed reward/cost functions, how should we optimize them and obtain driving policies that interact with the environment safely and efficiently. Such progress has raised another equally important question: \emph{what should we optimize}? Instead of manually specifying the reward functions, it is desired that we can extract what human drivers try to optimize from real traffic data and assign that to autonomous vehicles to enable more naturalistic and transparent interaction between humans and intelligent agents. To address this issue, we present an efficient sampling-based maximum-entropy inverse reinforcement learning (IRL) algorithm in this paper. Different from existing IRL algorithms, by introducing an efficient continuous-domain trajectory sampler, the proposed algorithm can directly learn the reward functions in the continuous domain while considering the uncertainties in demonstrated trajectories from human drivers. We evaluate the proposed algorithm on real driving data, including both non-interactive and interactive scenarios. The experimental results show that the proposed algorithm achieves more accurate prediction performance with faster convergence speed and better generalization compared to other baseline IRL algorithms.