 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Learning Rates with Maximum Variation Averaging
Paper and Code
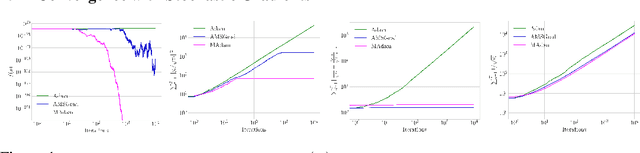


Adaptive gradient methods such as RMSProp and Adam use exponential moving estimate of the squared gradient to compute element-wise adaptive step sizes and handle noisy gradients. However, Adam can have undesirable convergence behavior in some problems due to unstable or extreme adaptive learning rates. Methods such as AMSGrad and AdaBound have been proposed to stabilize the adaptive learning rates of Adam in the later stage of training, but they do not outperform Adam in some practical tasks such as training Transformers. In this paper, we propose an adaptive learning rate rule in which the running mean squared gradient is replaced by a weighted mean, with weights chosen to maximize the estimated variance of each coordinate. This gives a worst-case estimate for the local gradient variance, taking smaller steps when large curvatures or noisy gradients are present, resulting in more desirable convergence behavior than Adam. We analyze and demonstrate the improved efficacy of our adaptive averaging approach on image classification, neural machine translation and natural language understanding tasks.