 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Independent and Multilingual/Mixlingual Speech-Driven Talking Head Generation Using Phonetic Posteriorgrams
Paper and Code
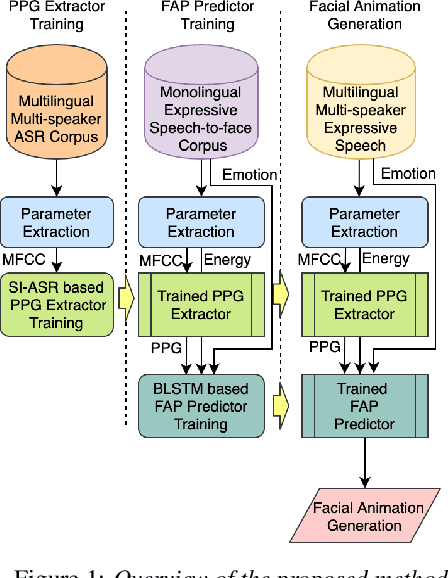
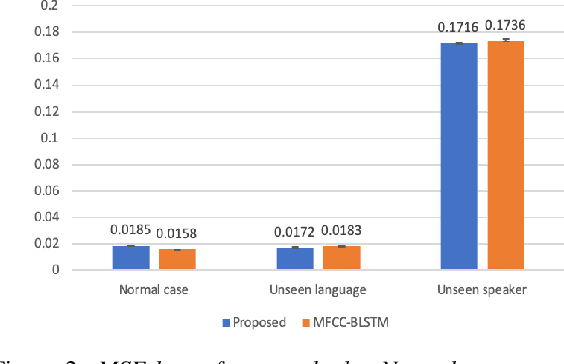
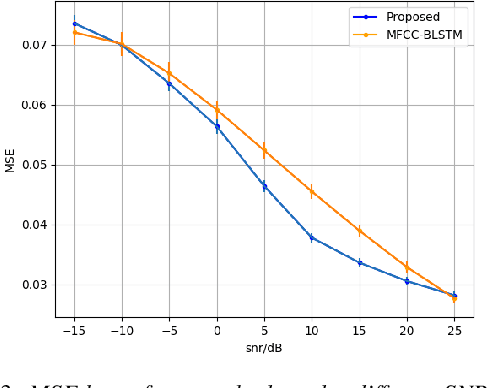
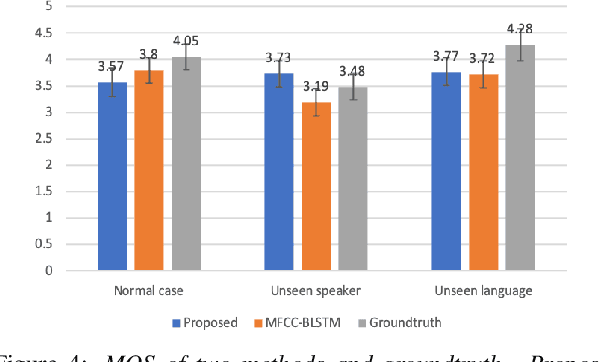
Generating 3D speech-driven talking head has received more and more attention in recent years. Recent approaches mainly have following limitations: 1) most speaker-independent methods need handcrafted features that are time-consuming to design or unreliable; 2) there is no convincing method to support multilingual or mixlingual speech as input. In this work, we propose a novel approach using phonetic posteriorgrams (PPG). In this way, our method doesn't need hand-crafted features and is more robust to noise compared to recent approaches. Furthermore, our method can support multilingual speech as input by building a universal phoneme space. As far as we know, our model is the first to support multilingual/mixlingual speech as input with convincing results. Objective and subjective experiments have shown that our model can generate high quality animations given speech from unseen languages or speakers and be robust to noise.