 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Vehicle Re-identification with Progressive Adaptation
Paper and Code
Jun 20, 2020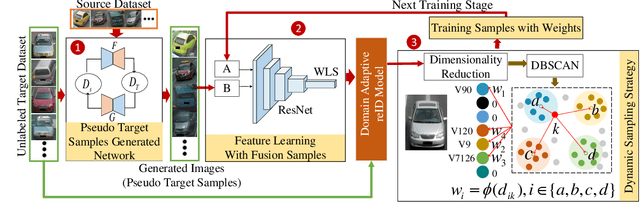
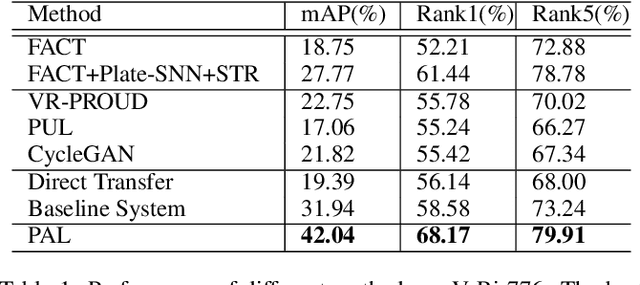
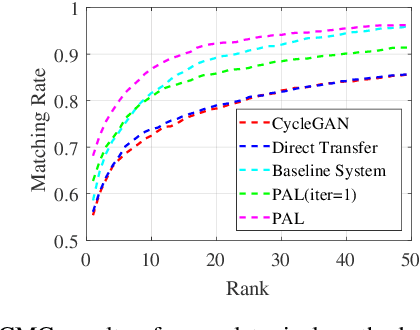

Vehicle re-identification (reID) aims at identifying vehicles across different non-overlapping cameras views. The existing methods heavily relied on well-labeled datasets for ideal performance, which inevitably causes fateful drop due to the severe domain bias between the training domain and the real-world scenes; worse still, these approaches required full annotations, which is labor-consuming. To tackle these challenges, we propose a novel progressive adaptation learning method for vehicle reID, named PAL, which infers from the abundant data without annotations. For PAL, a data adaptation module is employed for source domain, which generates the images with similar data distribution to unlabeled target domain as ``pseudo target samples''. These pseudo samples are combined with the unlabeled samples that are selected by a dynamic sampling strategy to make training faster. We further proposed a weighted label smoothing (WLS) loss, which considers the similarity between samples with different clusters to balance the confidence of pseudo labels. Comprehensive experimental results validate the advantages of PAL on both VehicleID and VeRi-776 dataset.