 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocBank: A Benchmark Dataset for Document Layout Analysis
Paper and Code

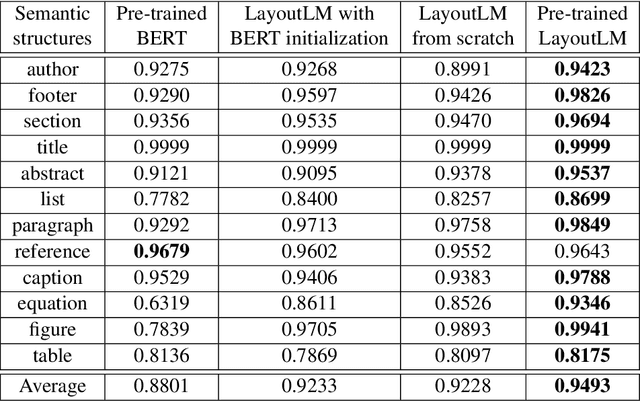

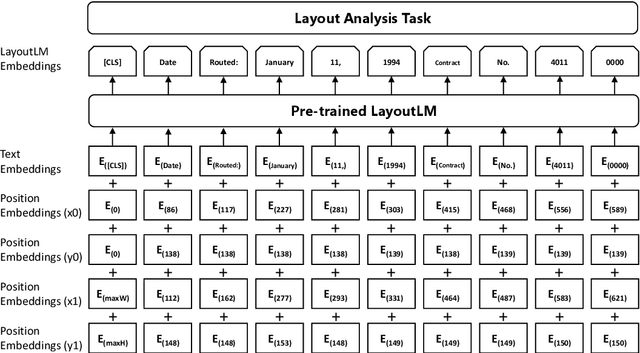
Document layout analysis usually relies on computer vision models to understand documents while ignoring textual information that is vital to capture. Meanwhile, high quality labeled datasets with both visual and textual information are still insufficient. In this paper, we present \textbf{DocBank}, a benchmark dataset with fine-grained token-level annotations for document layout analysis. DocBank is constructed using a simple yet effective way with weak supervision from the \LaTeX{} documents available on the arXiv.com. With DocBank, models from different modalities can be compared fairly and multi-modal approaches will be further investigated and boost the performance of document layout analysis. We build several strong baselines and manually split train/dev/test sets for evaluation. Experiment results show that models trained on DocBank accurately recognize the layout information for a variety of documents. The DocBank dataset will be publicly available at \url{https://github.com/doc-analysis/DocBank}.