Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Localization Using Semantic Segmentation and Depth Prediction
Paper and Code
May 25, 2020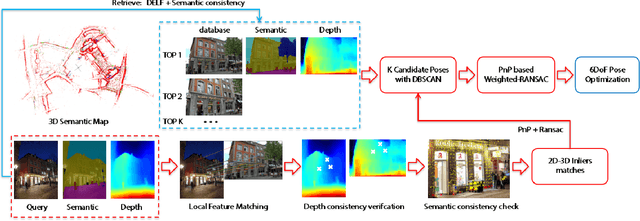


In this paper, we propose a monocular visual localization pipeline leveraging semantic and depth cues. We apply semantic consistency evaluation to rank the image retrieval results and a practical clustering technique to reject estimation outliers. In addition, we demonstrate a substantial performance boost achieved with a combination of multiple feature extractors. Furthermore, by using depth prediction with a deep neural network, we show that a significant amount of falsely matched keypoints are identified and eliminated. The proposed pipeline outperforms most of the existing approaches at the Long-Term Visual Localization benchmark 2020.
View paper on