 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind the Scene: Revealing the Secrets of Pre-trained Vision-and-Language Models
Paper and Code
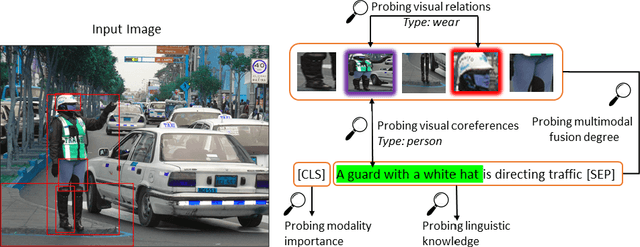

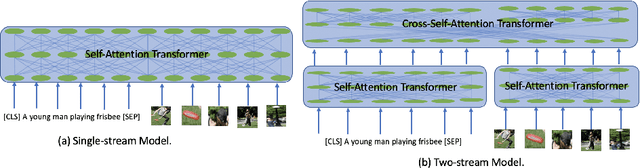
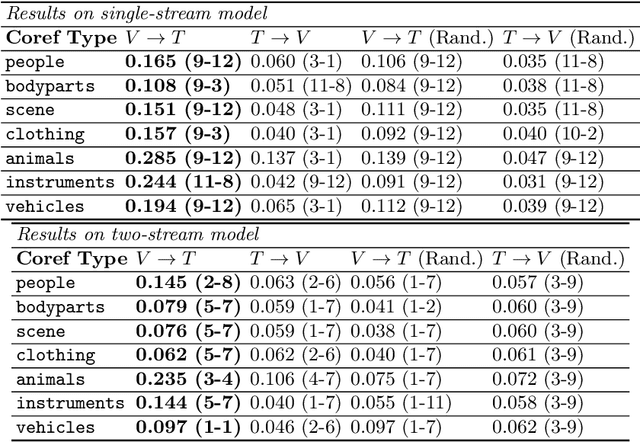
Recent Transformer-based large-scale pre-trained models have revolutionized vision-and-language (V+L) research. Models such as ViLBERT, LXMERT and UNITER have significantly lifted state of the art across a wide range of V+L benchmarks with joint image-text pre-training. However, little is known about the inner mechanisms that destine their impressive success. To reveal the secrets behind the scene of these powerful models, we present VALUE (Vision-And-Language Understanding Evaluation), a set of meticulously designed probing tasks (e.g., Visual Coreference Resolution, Visual Relation Detection, Linguistic Probing Tasks) generalizable to standard pre-trained V+L models, aiming to decipher the inner workings of multimodal pre-training (e.g., the implicit knowledge garnered in individual attention heads, the inherent cross-modal alignment learned through contextualized multimodal embeddings). Through extensive analysis of each archetypal model architecture via these probing tasks, our key observations are: (i) Pre-trained models exhibit a propensity for attending over text rather than images during inference. (ii) There exists a subset of attention heads that are tailored for capturing cross-modal interactions. (iii) Learned attention matrix in pre-trained models demonstrates patterns coherent with the latent alignment between image regions and textual words. (iv) Plotted attention patterns reveal visually-interpretable relations among image regions. (v) Pure linguistic knowledge is also effectively encoded in the attention heads. These are valuable insights serving to guide future work towards designing better model architecture and objectives for multimodal pre-training.