 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
Paper and Code
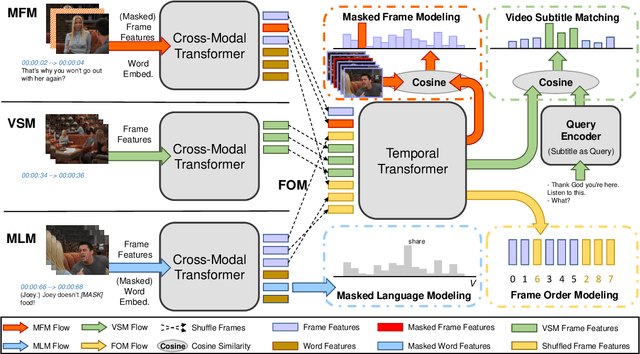
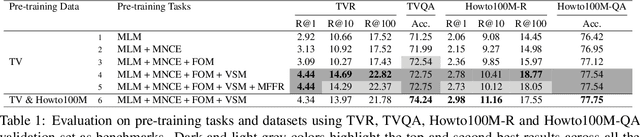
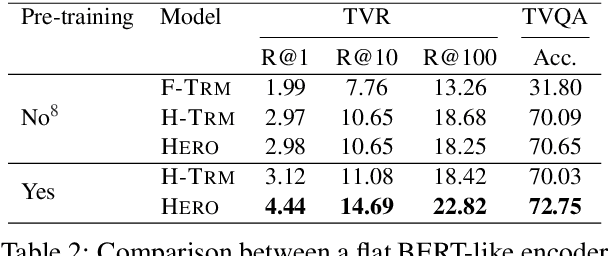
We present HERO, a Hierarchical EncodeR for Omni-representation learning, for large-scale video+language pre-training. HERO encodes multimodal inputs in a hierarchical fashion, where local textual context of a video frame is captured by a Cross-modal Transformer via multimodal fusion, and global video context is captured by a Temporal Transformer. Besides standard Masked Language Modeling (MLM) and Masked Frame Modeling (MFM) objectives, we design two new pre-training tasks: (i) Video-Subtitle Matching (VSM), where the model predicts both global and local temporal alignment; and (ii) Frame Order Modeling (FOM), where the model predicts the right order of shuffled video frames. Different from previous work that mostly focused on cooking or narrated instructional videos, HERO is jointly trained on HowTo100M and large-scale TV show datasets to learn complex social scenes, dynamics backdrop transitions and multi-character interactions. Extensive experiments demonstrate that HERO achieves new state of the art on both text-based video moment retrieval and video question answering tasks across different domains.