 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Correspondence via 2D-3D-2D Cycle
Paper and Code
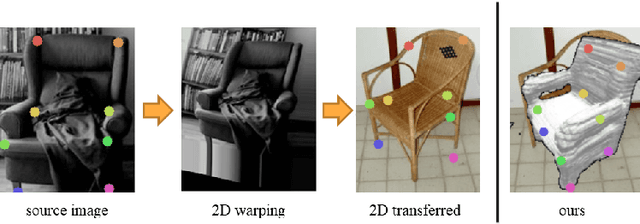
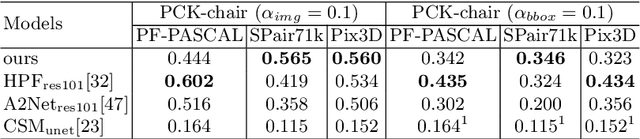
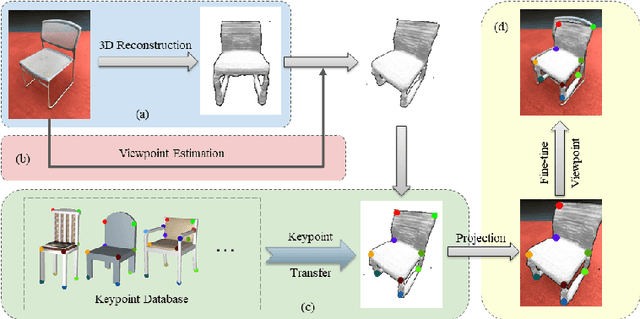

Visual semantic correspondence is an important topic in computer vision and could help machine understand objects in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting semantic correspondences by leveraging it to 3D domain and then project corresponding 3D models back to 2D domain, with their semantic labels. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks. We also conduct thorough and detailed experiments to analyze our network components. The code and experiments are publicly available at https://github.com/qq456cvb/SemanticTransfer.