 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deep Reinforcement Learning against Adversarial Perturbations on Observations
Paper and Code
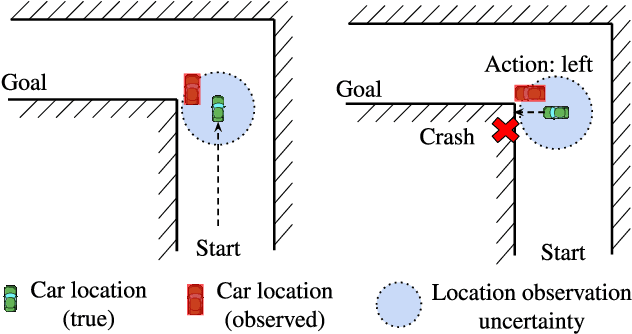

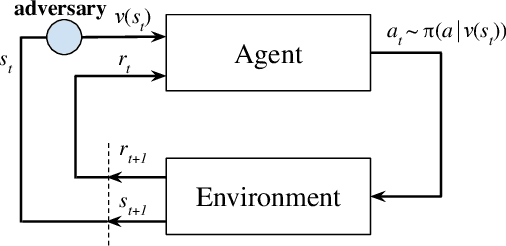
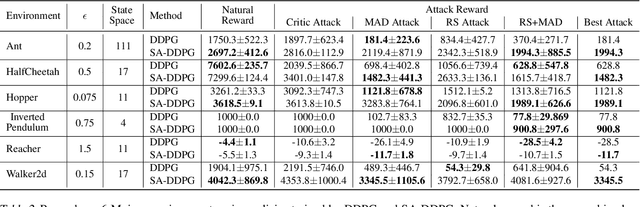
Deep Reinforcement Learning (DRL) is vulnerable to small adversarial perturbations on state observations. These perturbations do not alter the environment directly but can mislead the agent into making suboptimal decisions. We analyze the Markov Decision Process (MDP) under this threat model and utilize tools from the neural net-work verification literature to enable robust train-ing for DRL under observational perturbations. Our techniques are general and can be applied to both Deep Q Networks (DQN) and Deep Deterministic Policy Gradient (DDPG) algorithms for discrete and continuous action control problems. We demonstrate that our proposed training procedure significantly improves the robustness of DQN and DDPG agents under a suite of strong white-box attacks on observations, including a few novel attacks we specifically craft. Additionally, our training procedure can produce provable certificates for the robustness of a Deep RL agent.