 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 2D-3D Correspondences To Solve The Blind Perspective-n-Point Problem
Paper and Code
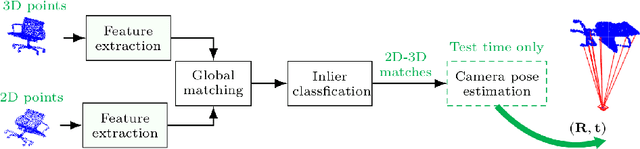

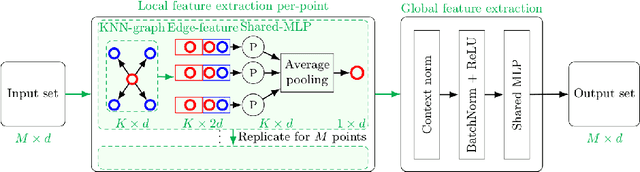

Conventional absolute camera pose via a Perspective-n-Point (PnP) solver often assumes that the correspondences between 2D image pixels and 3D points are given. When the correspondences between 2D and 3D points are not known a priori, the task becomes the much more challenging blind PnP problem. This paper proposes a deep CNN model which simultaneously solves for both the 6-DoF absolute camera pose and 2D--3D correspondences. Our model comprises three neural modules connected in sequence. First, a two-stream PointNet-inspired network is applied directly to both the 2D image keypoints and the 3D scene points in order to extract discriminative point-wise features harnessing both local and contextual information. Second, a global feature matching module is employed to estimate a matchability matrix among all 2D--3D pairs. Third, the obtained matchability matrix is fed into a classification module to disambiguate inlier matches. The entire network is trained end-to-end, followed by a robust model fitting (P3P-RANSAC) at test time only to recover the 6-DoF camera pose. Extensive tests on both real and simulated data have shown that our method substantially outperforms existing approaches, and is capable of processing thousands of points a second with the state-of-the-art accuracy.