 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Hashing Methods
Paper and Code
Mar 04, 2020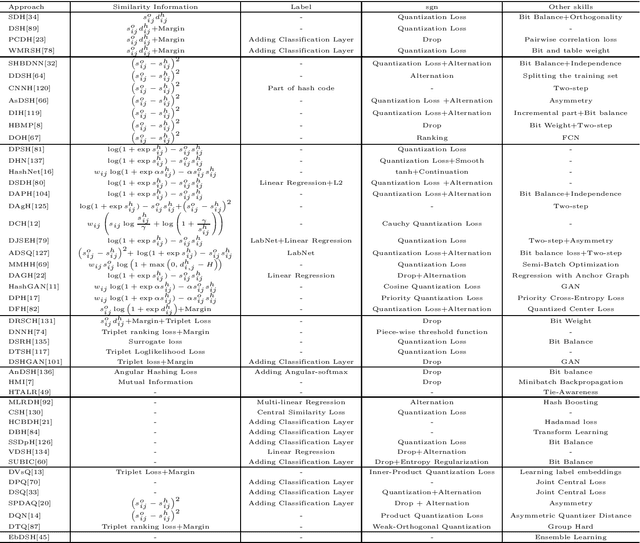
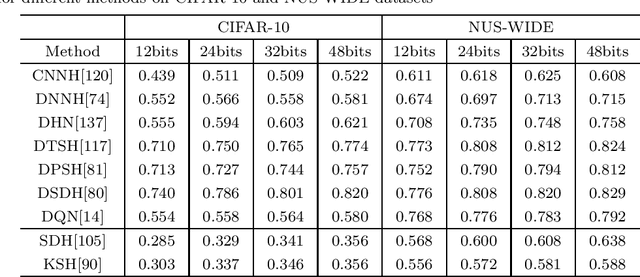
Nearest neighbor search is to find the data points in the database such that the distances from them to the query are the smallest, which is a fundamental problem in various domains, such as computer vision, recommendation systems and machine learning. Hashing is one of the most widely used method for its computational and storage efficiency. With the development of deep learning, deep hashing methods show more advantages than traditional methods. In this paper, we present a comprehensive survey of the deep hashing algorithms. Based on the loss function, we categorize deep supervised hashing methods according to the manners of preserving the similarities into: pairwise similarity preserving, multiwise similarity preserving, implicit similarity preserving, as well as quantization. In addition, we also introduce some other topics such as deep unsupervised hashing and multi-modal deep hashing methods. Meanwhile, we also present some commonly used public datasets and the scheme to measure the performance of deep hashing algorithms. Finally, we discussed some potential research directions in the conclusion.