 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Conditioning Analysis in Exploring the Learning Dynamics of DNNs
Paper and Code
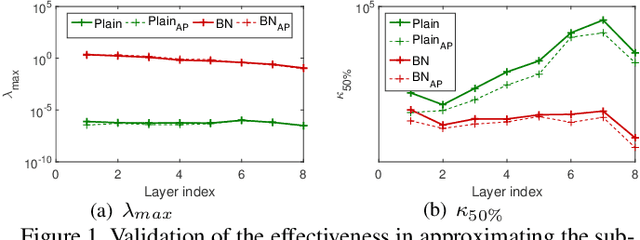

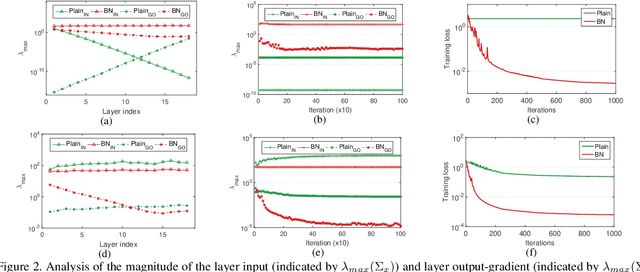

Conditioning analysis uncovers the landscape of an optimization objective by exploring the spectrum of its curvature matrix. This has been well explored theoretically for linear models. We extend this analysis to deep neural networks (DNNs) in order to investigate their learning dynamics. To this end, we propose layer-wise conditioning analysis, which explores the optimization landscape with respect to each layer independently. Such an analysis is theoretically supported under mild assumptions that approximately hold in practice. Based on our analysis, we show that batch normalization (BN) can stabilize the training, but sometimes result in the false impression of a local minimum, which has detrimental effects on the learning. Besides, we experimentally observe that BN can improve the layer-wise conditioning of the optimization problem. Finally, we find that the last linear layer of a very deep residual network displays ill-conditioned behavior. We solve this problem by only adding one BN layer before the last linear layer, which achieves improved performance over the original and pre-activation residual networks.