 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Distillation Loss: Generic Approach for Improving Face Recognition from Hard Samples
Paper and Code
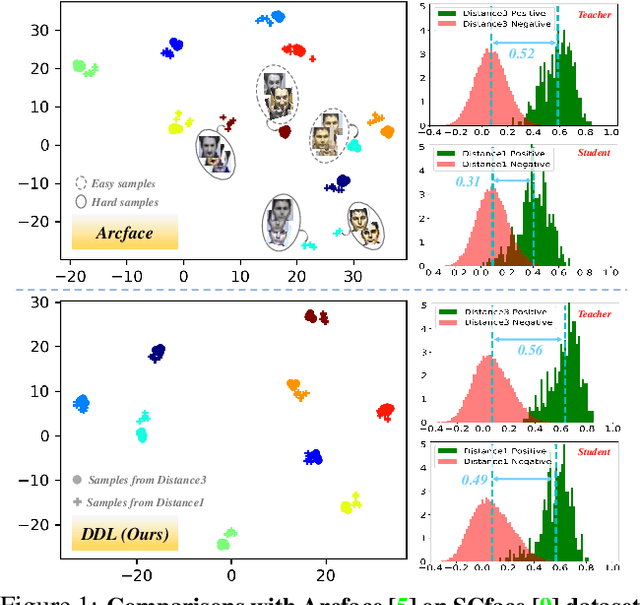
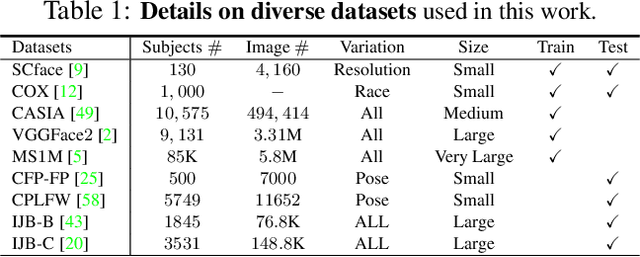
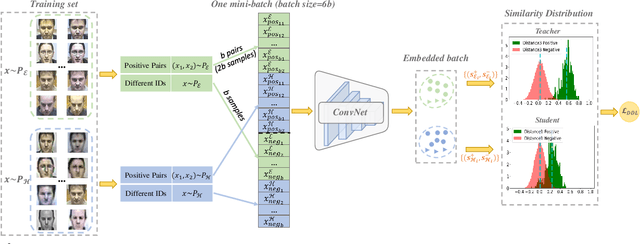
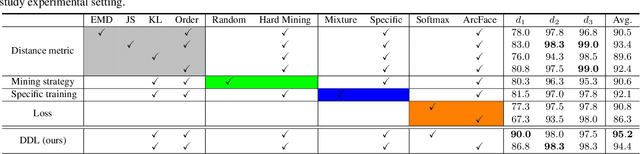
Large facial variations are the main challenge in face recognition. To this end, previous variation-specific methods make full use of task-related prior to design special network losses, which are typically not general among different tasks and scenarios. In contrast, the existing generic methods focus on improving the feature discriminability to minimize the intra-class distance while maximizing the interclass distance, which perform well on easy samples but fail on hard samples. To improve the performance on those hard samples for general tasks, we propose a novel Distribution Distillation Loss to narrow the performance gap between easy and hard samples, which is a simple, effective and generic for various types of facial variations. Specifically, we first adopt state-of-the-art classifiers such as ArcFace to construct two similarity distributions: teacher distribution from easy samples and student distribution from hard samples. Then, we propose a novel distribution-driven loss to constrain the student distribution to approximate the teacher distribution, which thus leads to smaller overlap between the positive and negative pairs in the student distribution. We have conducted extensive experiments on both generic large-scale face benchmarks and benchmarks with diverse variations on race, resolution and pose. The quantitative results demonstrate the superiority of our method over strong baselines, e.g., Arcface and Cosface.