 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Feature based Graph Self-adaptive Pooling
Paper and Code
Jan 30, 2020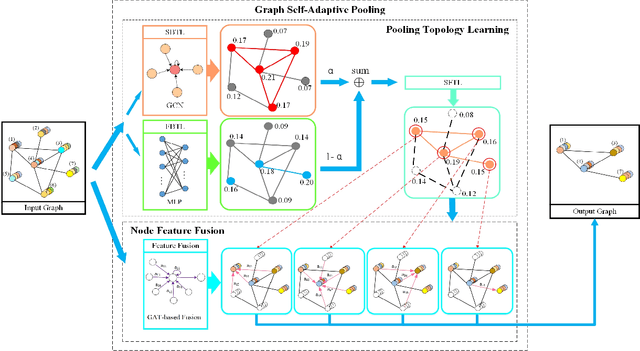

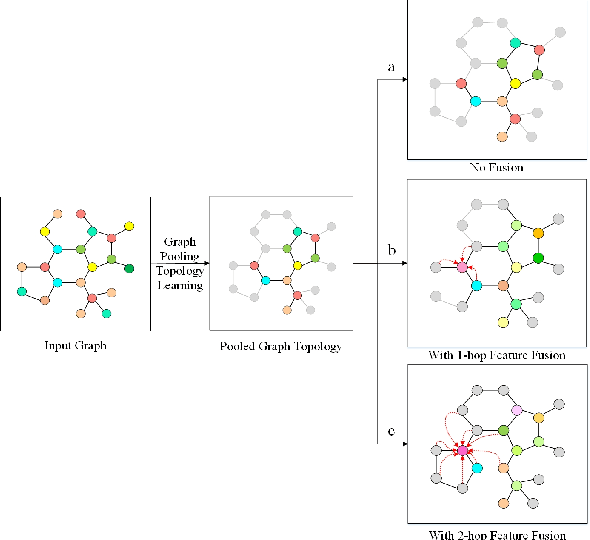
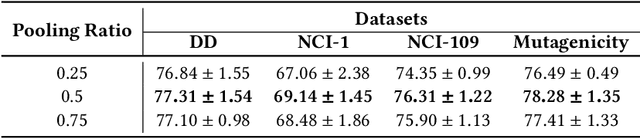
Various methods to deal with graph data have been proposed in recent years. However, most of these methods focus on graph feature aggregation rather than graph pooling. Besides, the existing top-k selection graph pooling methods have a few problems. First, to construct the pooled graph topology, current top-k selection methods evaluate the importance of the node from a single perspective only, which is simplistic and unobjective. Second, the feature information of unselected nodes is directly lost during the pooling process, which inevitably leads to a massive loss of graph feature information. To solve these problems mentioned above, we propose a novel graph self-adaptive pooling method with the following objectives: (1) to construct a reasonable pooled graph topology, structure and feature information of the graph are considered simultaneously, which provide additional veracity and objectivity in node selection; and (2) to make the pooled nodes contain sufficiently effective graph information, node feature information is aggregated before discarding the unimportant nodes; thus, the selected nodes contain information from neighbor nodes, which can enhance the use of features of the unselected nodes. Experimental results on four different datasets demonstrate that our method is effective in graph classification and outperforms state-of-the-art graph pooling methods.