 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDNNchip: An Automated DNN Chip Predictor and Builder for Both FPGAs and ASICs
Paper and Code
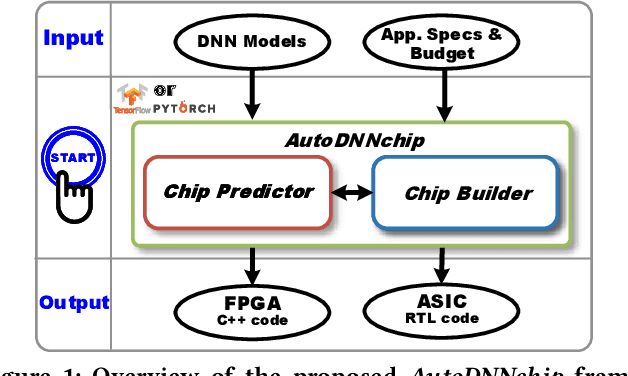
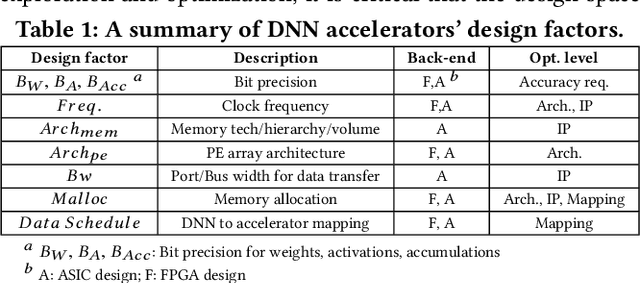
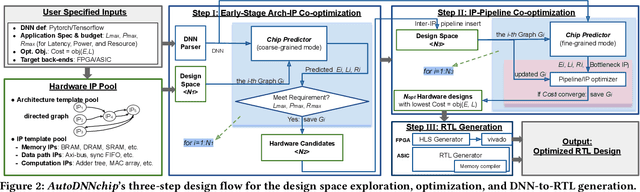

Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a growing demand for DNN chips. However, designing DNN chips is non-trivial because: (1) mainstream DNNs have millions of parameters and operations; (2) the large design space due to the numerous design choices of dataflows, processing elements, memory hierarchy, etc.; and (3) an algorithm/hardware co-design is needed to allow the same DNN functionality to have a different decomposition, which would require different hardware IPs to meet the application specifications. Therefore, DNN chips take a long time to design and require cross-disciplinary experts. To enable fast and effective DNN chip design, we propose AutoDNNchip - a DNN chip generator that can automatically generate both FPGA- and ASIC-based DNN chip implementation given DNNs from machine learning frameworks (e.g., PyTorch) for a designated application and dataset. Specifically, AutoDNNchip consists of two integrated enablers: (1) a Chip Predictor, built on top of a graph-based accelerator representation, which can accurately and efficiently predict a DNN accelerator's energy, throughput, and area based on the DNN model parameters, hardware configuration, technology-based IPs, and platform constraints; and (2) a Chip Builder, which can automatically explore the design space of DNN chips (including IP selection, block configuration, resource balancing, etc.), optimize chip design via the Chip Predictor, and then generate optimized synthesizable RTL to achieve the target design metrics. Experimental results show that our Chip Predictor's predicted performance differs from real-measured ones by < 10% when validated using 15 DNN models and 4 platforms (edge-FPGA/TPU/GPU and ASIC). Furthermore, accelerators generated by our AutoDNNchip can achieve better (up to 3.86X improvement) performance than that of expert-crafted state-of-the-art accelerators.