 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
Paper and Code
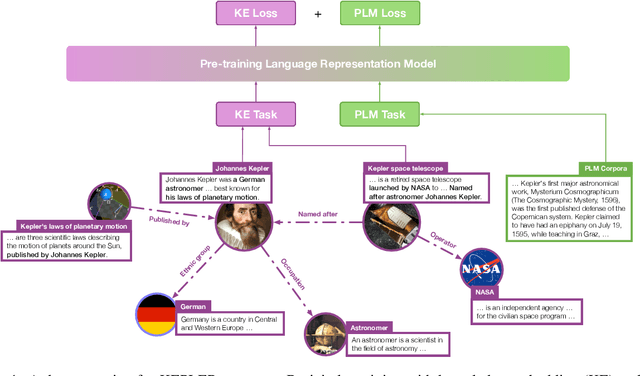
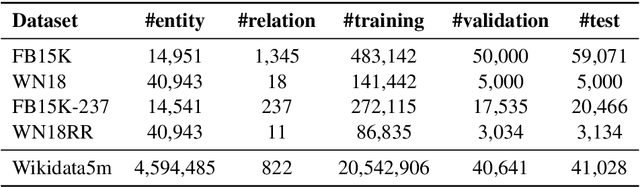
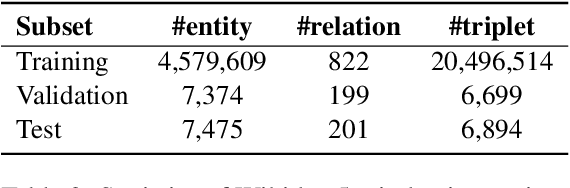
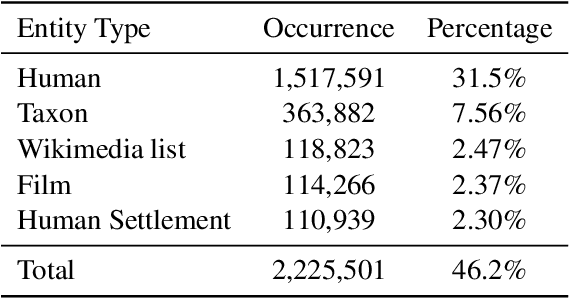
Pre-trained language representation models (PLMs) learn effective language representations from large-scale unlabeled corpora. Knowledge embedding (KE) algorithms encode the entities and relations in knowledge graphs into informative embeddings to do knowledge graph completion and provide external knowledge for various NLP applications. In this paper, we propose a unified model for Knowledge Embedding and Pre-trained LanguagE Representation (KEPLER), which not only better integrates factual knowledge into PLMs but also effectively learns knowledge graph embeddings. Our KEPLER utilizes a PLM to encode textual descriptions of entities as their entity embeddings, and then jointly learn the knowledge embeddings and language representations. Experimental results on various NLP tasks such as the relation extraction and the entity typing show that our KEPLER can achieve comparable results to the state-of-the-art knowledge-enhanced PLMs without any additional inference overhead. Furthermore, we construct Wikidata5m, a new large-scale knowledge graph dataset with aligned text descriptions, to evaluate KE embedding methods in both the traditional transductive setting and the challenging inductive setting, which needs the models to predict entity embeddings for unseen entities. Experiments demonstrate our KEPLER can achieve good results in both settings.