 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving One-shot NAS by Suppressing the Posterior Fading
Paper and Code
Oct 06, 2019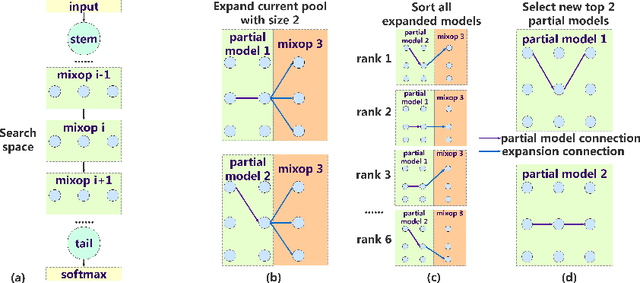
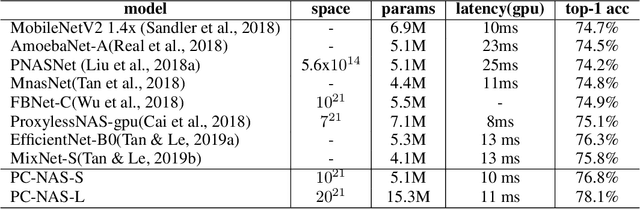

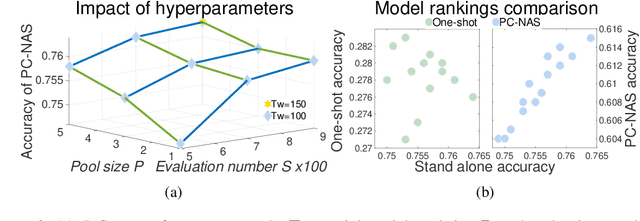
There is a growing interest in automated neural architecture search (NAS). To improve the efficiency of NAS, previous approaches adopt weight sharing method to force all models share the same set of weights. However, it has been observed that a model performing better with shared weights does not necessarily perform better when trained alone. In this paper, we analyse existing weight sharing one-shot NAS approaches from a Bayesian point of view and identify the posterior fading problem, which compromises the effectiveness of shared weights. To alleviate this problem, we present a practical approach to guide the parameter posterior towards its true distribution. Moreover, a hard latency constraint is introduced during the search so that the desired latency can be achieved. The resulted method, namely Posterior Convergent NAS (PC-NAS), achieves state-of-the-art performance under standard GPU latency constraint on ImageNet. In our small search space, our model PC-NAS-S attains 76.8 % top-1 accuracy, 2.1% higher than MobileNetV2 (1.4x) with the same latency. When adopted to the large search space, PC-NAS-L achieves 78.1 % top-1 accuracy within 11ms. The discovered architecture also transfers well to other computer vision applications such as object detection and person re-identification.