 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-based Localization Based on Domain-invariant Feature Learning under Changing Environments
Paper and Code
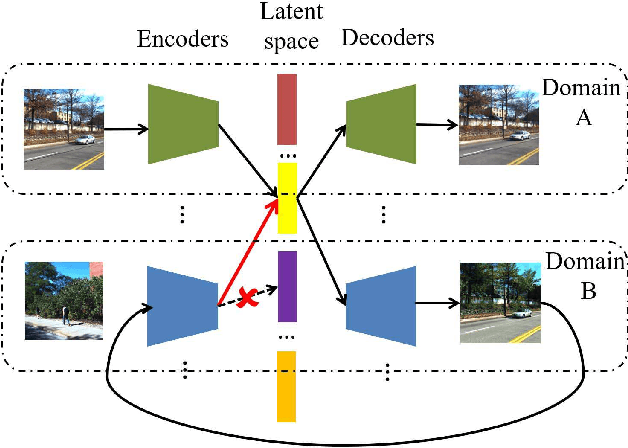
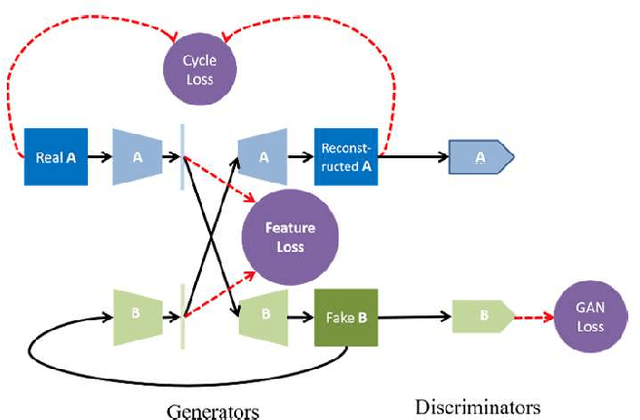
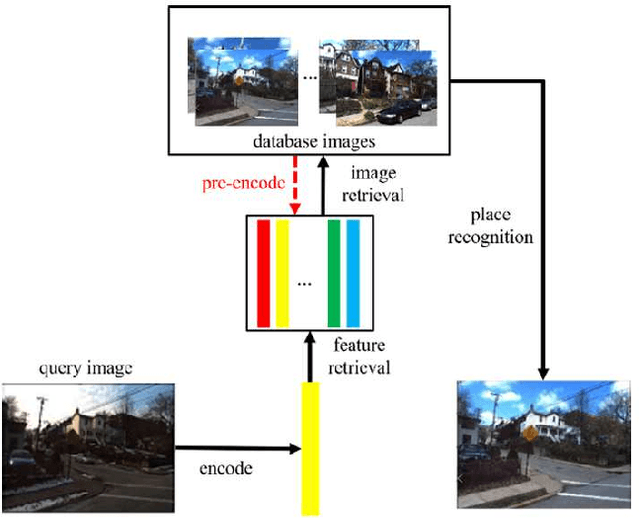
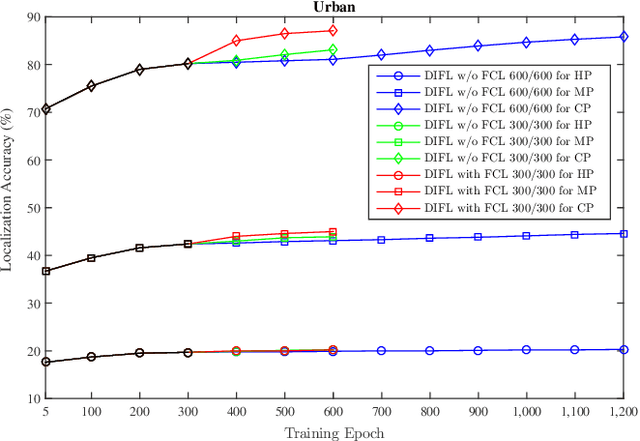
Visual localization is a crucial problem in mobile robotics and autonomous driving. One solution is to retrieve images with known pose from a database for the localization of query images. However, in environments with drastically varying conditions (e.g. illumination changes, seasons, occlusion, dynamic objects), retrieval-based localization is severely hampered and becomes a challenging problem. In this paper, a novel domain-invariant feature learning method (DIFL) is proposed based on ComboGAN, a multi-domain image translation network architecture. By introducing a feature consistency loss (FCL) between the encoded features of the original image and translated image in another domain, we are able to train the encoders to generate domain-invariant features in a self-supervised manner. To retrieve a target image from the database, the query image is first encoded using the encoder belonging to the query domain to obtain a domain-invariant feature vector. We then preform retrieval by selecting the database image with the most similar domain-invariant feature vector. We validate the proposed approach on the CMU-Seasons dataset, where we outperform state-of-the-art learning-based descriptors in retrieval-based localization for high and medium precision scenarios.