 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-sequence Pre-training with Data Augmentation for Sentence Rewriting
Paper and Code
Sep 20, 2019
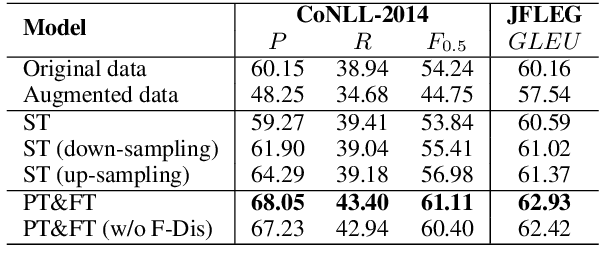
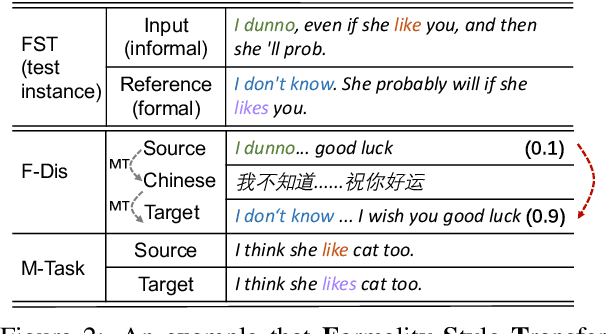
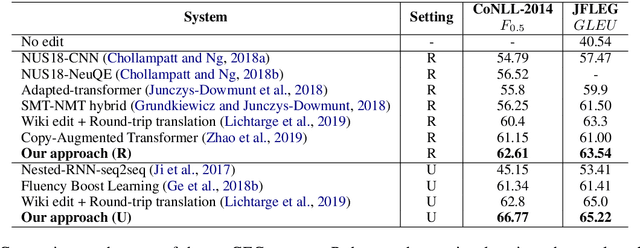
We study sequence-to-sequence (seq2seq) pre-training with data augmentation for sentence rewriting. Instead of training a seq2seq model with gold training data and augmented data simultaneously, we separate them to train in different phases: pre-training with the augmented data and fine-tuning with the gold data. We also introduce multiple data augmentation methods to help model pre-training for sentence rewriting. We evaluate our approach in two typical well-defined sentence rewriting tasks: Grammatical Error Correction (GEC) and Formality Style Transfer (FST). Experiments demonstrate our approach can better utilize augmented data without hurting the model's trust in gold data and further improve the model's performance with our proposed data augmentation methods. Our approach substantially advances the state-of-the-art results in well-recognized sentence rewriting benchmarks over both GEC and FST. Specifically, it pushes the CoNLL-2014 benchmark's $F_{0.5}$ score and JFLEG Test GLEU score to 62.61 and 63.54 in the restricted training setting, 66.77 and 65.22 respectively in the unrestricted setting, and advances GYAFC benchmark's BLEU to 74.24 (2.23 absolute improvement) in E&M domain and 77.97 (2.64 absolute improvement) in F&R domain.