 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-time Execution on Mobile Devices
Paper and Code
Sep 12, 2019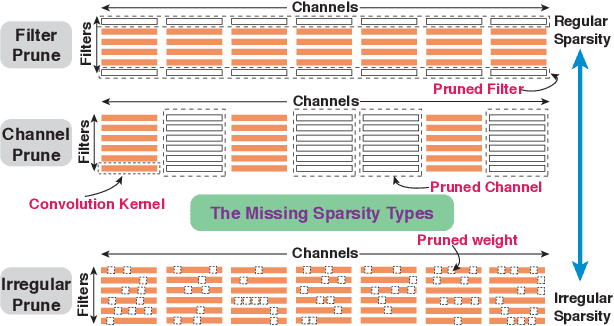
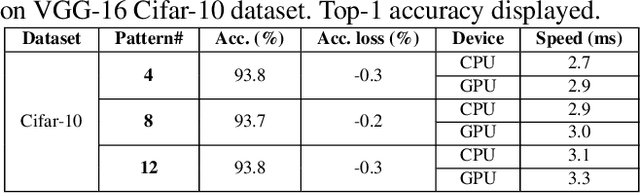
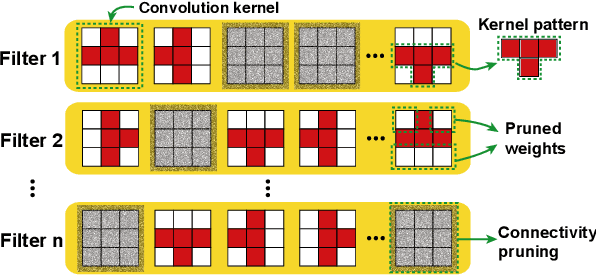
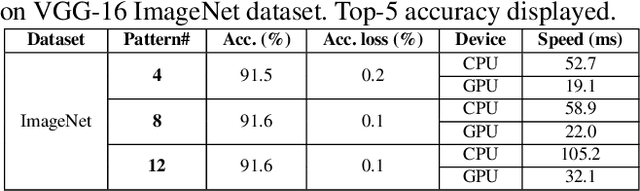
Model compression techniques on Deep Neural Network (DNN) have been widely acknowledged as an effective way to achieve acceleration on a variety of platforms, and DNN weight pruning is a straightforward and effective method. There are currently two mainstreams of pruning methods representing two extremes of pruning regularity: non-structured, fine-grained pruning can achieve high sparsity and accuracy, but is not hardware friendly; structured, coarse-grained pruning exploits hardware-efficient structures in pruning, but suffers from accuracy drop when the pruning rate is high. In this paper, we introduce PCONV, comprising a new sparsity dimension, -- fine-grained pruning patterns inside the coarse-grained structures. PCONV comprises two types of sparsities, Sparse Convolution Patterns (SCP) which is generated from intra-convolution kernel pruning and connectivity sparsity generated from inter-convolution kernel pruning. Essentially, SCP enhances accuracy due to its special vision properties, and connectivity sparsity increases pruning rate while maintaining balanced workload on filter computation. To deploy PCONV, we develop a novel compiler-assisted DNN inference framework and execute PCONV models in real-time without accuracy compromise, which cannot be achieved in prior work. Our experimental results show that, PCONV outperforms three state-of-art end-to-end DNN frameworks, TensorFlow-Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 39.2x, 11.4x, and 6.3x, respectively, with no accuracy loss. Mobile devices can achieve real-time inference on large-scale DNNs.