 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-end Video Text Detector with Online Tracking
Paper and Code
Aug 20, 2019
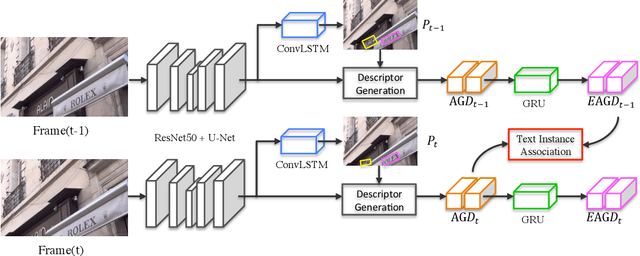
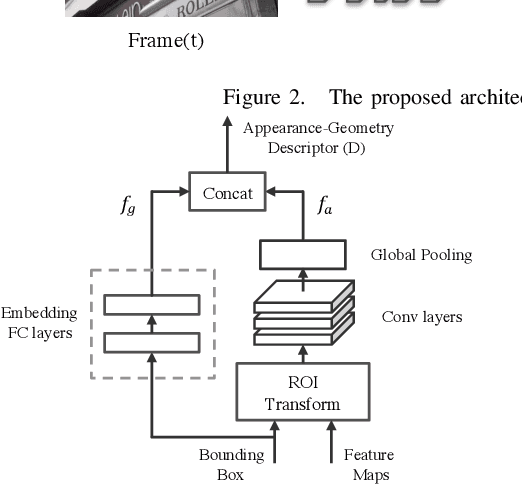
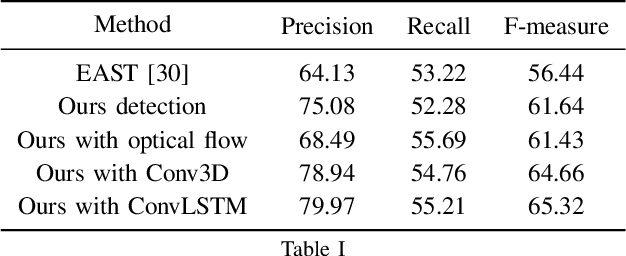
Video text detection is considered as one of the most difficult tasks in document analysis due to the following two challenges: 1) the difficulties caused by video scenes, i.e., motion blur, illumination changes, and occlusion; 2) the properties of text including variants of fonts, languages, orientations, and shapes. Most existing methods attempt to enhance the performance of video text detection by cooperating with video text tracking, but treat these two tasks separately. In this work, we propose an end-to-end video text detection model with online tracking to address these two challenges. Specifically, in the detection branch, we adopt ConvLSTM to capture spatial structure information and motion memory. In the tracking branch, we convert the tracking problem to text instance association, and an appearance-geometry descriptor with memory mechanism is proposed to generate robust representation of text instances. By integrating these two branches into one trainable framework, they can promote each other and the computational cost is significantly reduced. Experiments on existing video text benchmarks including ICDAR2013 Video, Minetto and YVT demonstrate that the proposed method significantly outperforms state-of-the-art methods. Our method improves F-score by about 2 on all datasets and it can run realtime with 24.36 fps on TITAN Xp.