 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle In Cycle Generative Adversarial Networks for Keypoint-Guided Image Generation
Paper and Code

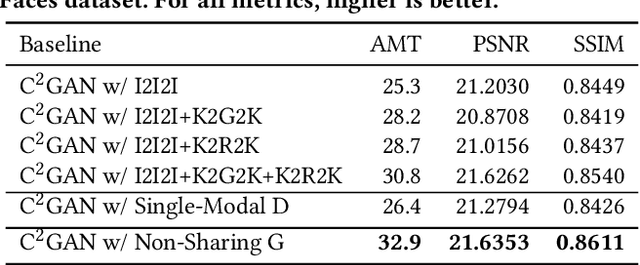
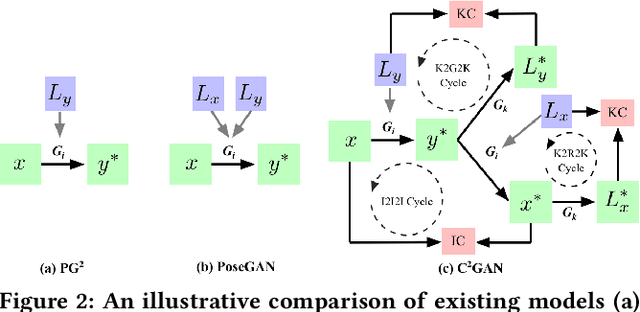
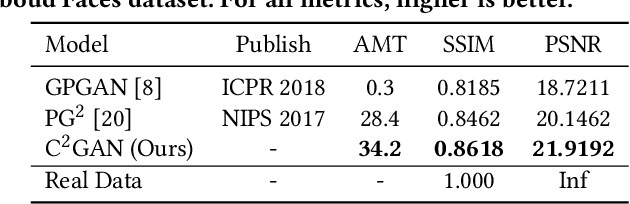
In this work, we propose a novel Cycle In Cycle Generative Adversarial Network (C$^2$GAN) for the task of keypoint-guided image generation. The proposed C$^2$GAN is a cross-modal framework exploring a joint exploitation of the keypoint and the image data in an interactive manner. C$^2$GAN contains two different types of generators, i.e., keypoint-oriented generator and image-oriented generator. Both of them are mutually connected in an end-to-end learnable fashion and explicitly form three cycled sub-networks, i.e., one image generation cycle and two keypoint generation cycles. Each cycle not only aims at reconstructing the input domain, and also produces useful output involving in the generation of another cycle. By so doing, the cycles constrain each other implicitly, which provides complementary information from the two different modalities and brings extra supervision across cycles, thus facilitating more robust optimization of the whole network. Extensive experimental results on two publicly available datasets, i.e., Radboud Faces and Market-1501, demonstrate that our approach is effective to generate more photo-realistic images compared with state-of-the-art models.