 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedure Planning in Instructional Videos
Paper and Code
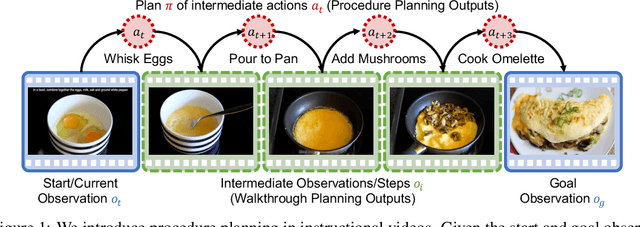
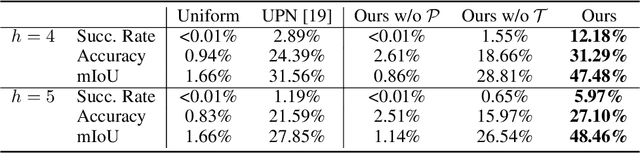
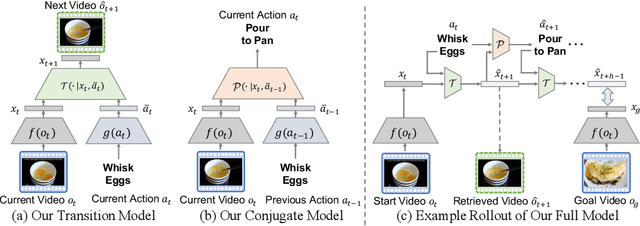
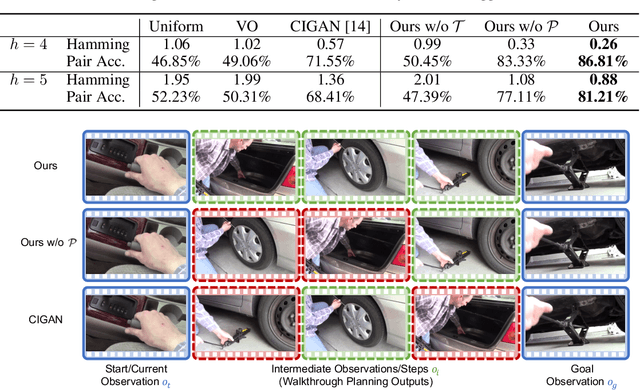
We propose a new challenging task: procedure planning in instructional videos. Unlike existing planning problems, where both the state and the action spaces are well-defined, the key challenge of planning in instructional videos is that both the state and the action spaces are open-vocabulary. We address this challenge with latent space planning, where we propose to explicitly leverage the constraints imposed by the conjugate relationships between states and actions in a learned plannable latent space. We evaluate both procedure planning and walkthrough planning on large-scale real-world instructional videos. Our experiments show that we are able to learn plannable semantic representations without explicit supervision. This enables sequential reasoning on real-world videos and leads to stronger generalization compared to existing planning approaches and neural network policies.