 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple-to-Text: Converting RDF Triples into High-Quality Natural Languages via Optimizing an Inverse KL Divergence
Paper and Code
May 25, 2019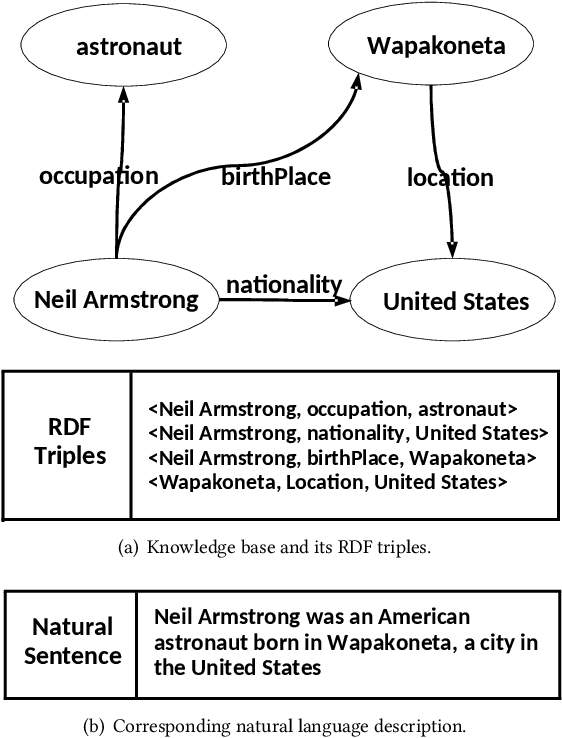


Knowledge base is one of the main forms to represent information in a structured way. A knowledge base typically consists of Resource Description Frameworks (RDF) triples which describe the entities and their relations. Generating natural language description of the knowledge base is an important task in NLP, which has been formulated as a conditional language generation task and tackled using the sequence-to-sequence framework. Current works mostly train the language models by maximum likelihood estimation, which tends to generate lousy sentences. In this paper, we argue that such a problem of maximum likelihood estimation is intrinsic, which is generally irrevocable via changing network structures. Accordingly, we propose a novel Triple-to-Text (T2T) framework, which approximately optimizes the inverse Kullback-Leibler (KL) divergence between the distributions of the real and generated sentences. Due to the nature that inverse KL imposes large penalty on fake-looking samples, the proposed method can significantly reduce the probability of generating low-quality sentences. Our experiments on three real-world datasets demonstrate that T2T can generate higher-quality sentences and outperform baseline models in several evaluation metrics.