 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Reasoning using Prior Knowledge for Visual Captioning
Paper and Code
Jun 04, 2019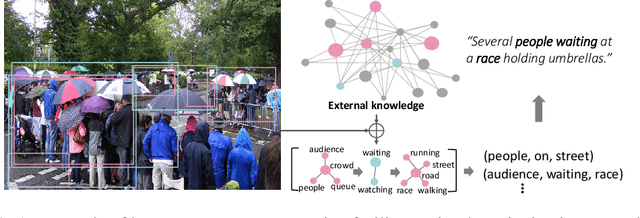
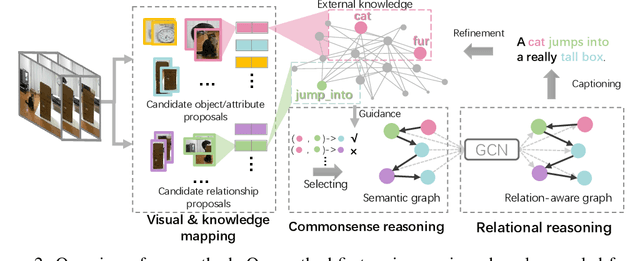

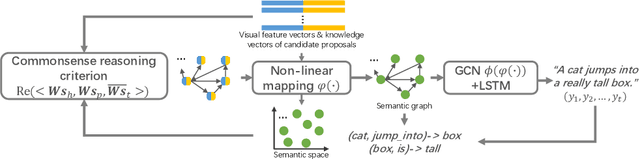
Exploiting relationships among objects has achieved remarkable progress in interpreting images or videos by natural language. Most existing methods resort to first detecting objects and their relationships, and then generating textual descriptions, which heavily depends on pre-trained detectors and leads to performance drop when facing problems of heavy occlusion, tiny-size objects and long-tail in object detection. In addition, the separate procedure of detecting and captioning results in semantic inconsistency between the pre-defined object/relation categories and the target lexical words. We exploit prior human commonsense knowledge for reasoning relationships between objects without any pre-trained detectors and reaching semantic coherency within one image or video in captioning. The prior knowledge (e.g., in the form of knowledge graph) provides commonsense semantic correlation and constraint between objects that are not explicit in the image and video, serving as useful guidance to build semantic graph for sentence generation. Particularly, we present a joint reasoning method that incorporates 1) commonsense reasoning for embedding image or video regions into semantic space to build semantic graph and 2) relational reasoning for encoding semantic graph to generate sentences. Extensive experiments on the MS-COCO image captioning benchmark and the MSVD video captioning benchmark validate the superiority of our method on leveraging prior commonsense knowledge to enhance relational reasoning for visual captioning.