 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying through a narrow gap using neural network: an end-to-end planning and control approach
Paper and Code

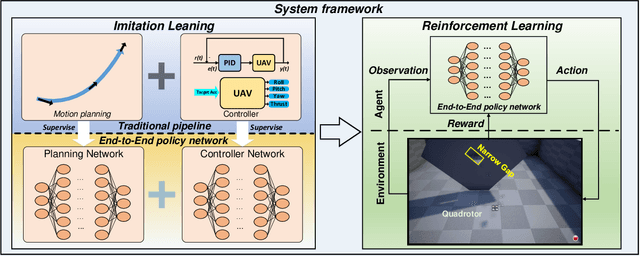
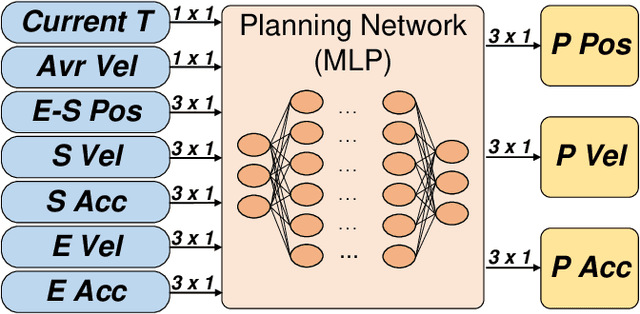
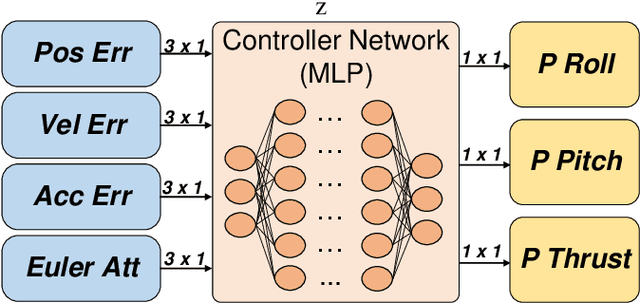
In this paper, we investigate the problem of enabling a drone to fly through a tilted narrow gap, without a traditional planning and control pipeline. To this end, we propose an end-to-end policy network, which imitates from the traditional pipeline and is fine-tuned using reinforcement learning. Unlike previous works which plan dynamical feasible trajectories using motion primitives and track the generated trajectory by a geometric controller, our proposed method is an end-to-end approach which takes the flight scenario as input and directly outputs thrust-attitude control commands for the quadrotor. Key contributions of our paper are: 1) presenting an imitate-reinforce training framework. 2) flying through a narrow gap using an end-to-end policy network, showing that learning based method can also address the highly dynamic control problem as the traditional pipeline does (see attached video: https://www.youtube.com/watch?v=jU1qRcLdjx0). 3) propose a robust imitation of an optimal trajectory generator using multilayer perceptrons. 4) show how reinforcement learning can improve the performance of imitation learning, and the potential to achieve higher performance over the model-based method.