 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Look & Listen Once: Towards Fast and Accurate Visual Grounding
Paper and Code
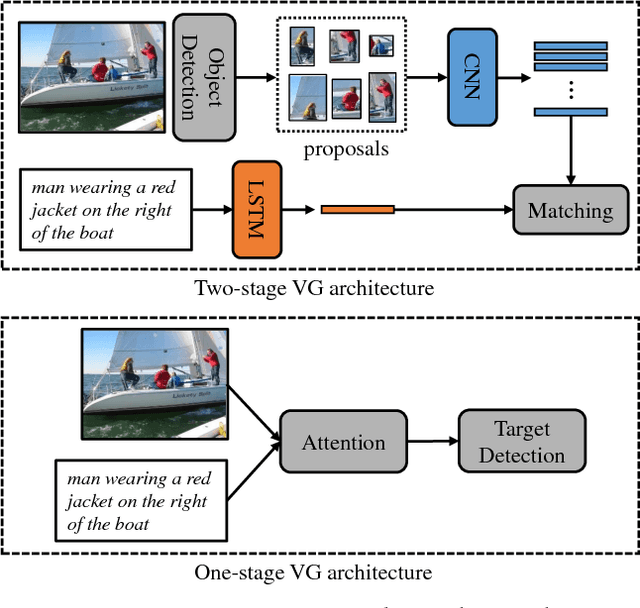
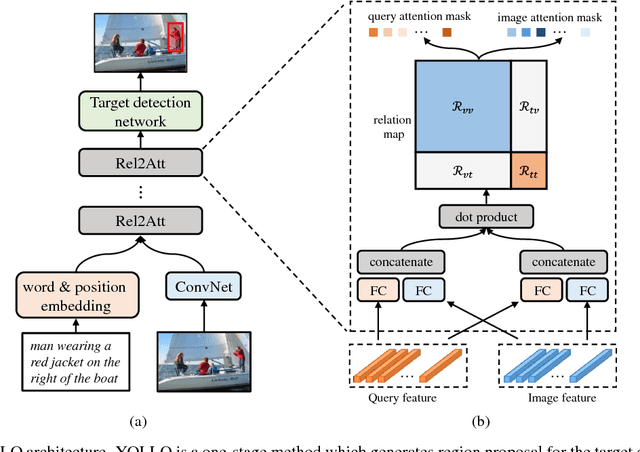
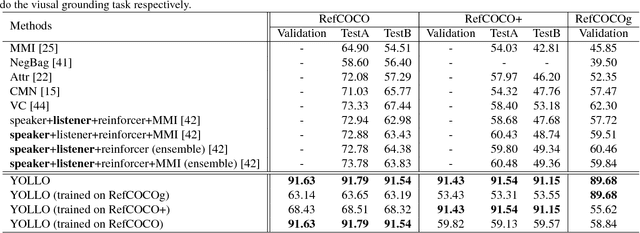
Visual Grounding (VG) aims to locate the most relevant region in an image, based on a flexible natural language query but not a pre-defined label, thus it can be a more useful technique than object detection in practice. Most state-of-the-art methods in VG operate in a two-stage manner, wherein the first stage an object detector is adopted to generate a set of object proposals from the input image and the second stage is simply formulated as a cross-modal matching problem that finds the best match between the language query and all region proposals. This is rather inefficient because there might be hundreds of proposals produced in the first stage that need to be compared in the second stage, not to mention this strategy performs inaccurately. In this paper, we propose an simple, intuitive and much more elegant one-stage detection based method that joints the region proposal and matching stage as a single detection network. The detection is conditioned on the input query with a stack of novel Relation-to-Attention modules that transform the image-to-query relationship to an relation map, which is used to predict the bounding box directly without proposing large numbers of useless region proposals. During the inference, our approach is about 20x ~ 30x faster than previous methods and, remarkably, it achieves 18% ~ 41% absolute performance improvement on top of the state-of-the-art results on several benchmark datasets. We release our code and all the pre-trained models at https://github.com/openblack/rvg.